
Netflix、Oracle、ING、思科、JFrog 都如何做 DevOps 的?
今天我分享的主题是《一站式软件交付:世界五百强企业的 DevOps 转型之道》,会讲到国内外的一些大型企业是怎么实现 DevOps 落地的,以及企业决策者通常会关注哪些 DevOps 带来的收益,希望本次分享可以帮助大家说服领导快速落地 DevOps,提升企业的竞争力。
软件开发趋势

众所周知,敏捷开发带来的是持续测试的能力,是把开发和测试的团队合在一起,实现一些持续测试。 DevOps 目前主要做的事情是实现持续部署、持续交付,现在可以用一些灰度发布、金丝雀发布去做小规模的发布,但只是发布应用到某一部分的集群。
就像谷歌所做的,比如 Google 地图现在想发布某个新功能,会先在公司内部发布或者是做一个小规模的发布,后面再做一些对外的发布,这是 DevOps 带来的一个好处。

此外,DevOps 还需要一些工具去实现。在构建方面,我们看到互联网公司里 80% 都在用 Jenkins,因为 Jenkins 做实时构建、实时编译,平台本身是非常开放的,也有很多的插件可以支持单元测试、性能测试 。如果用付费版的软件,国外有一些做容器编译的比如 CircleCI 等。在测试环节,很多工具都是免费的,比如 Junit、Jmeter 等。在部署方面,国内外主要是 Ansible 和 Saltstack 这两个用得最多,我们也有一些比较酷的工具,后面会展开介绍。
DevOps 的工具链特别多,也比较复杂,所以企业要想办法去支持所有的工具链,因为我想要开发团队能够自由使用他们想用的工具,帮他们提高研发效率,而不是强制他去用某几种工具,所以落地 DevOps 平台是很重要的,因为需要用 API 的方式去对接各个工具链。
DevOps 的发展现状
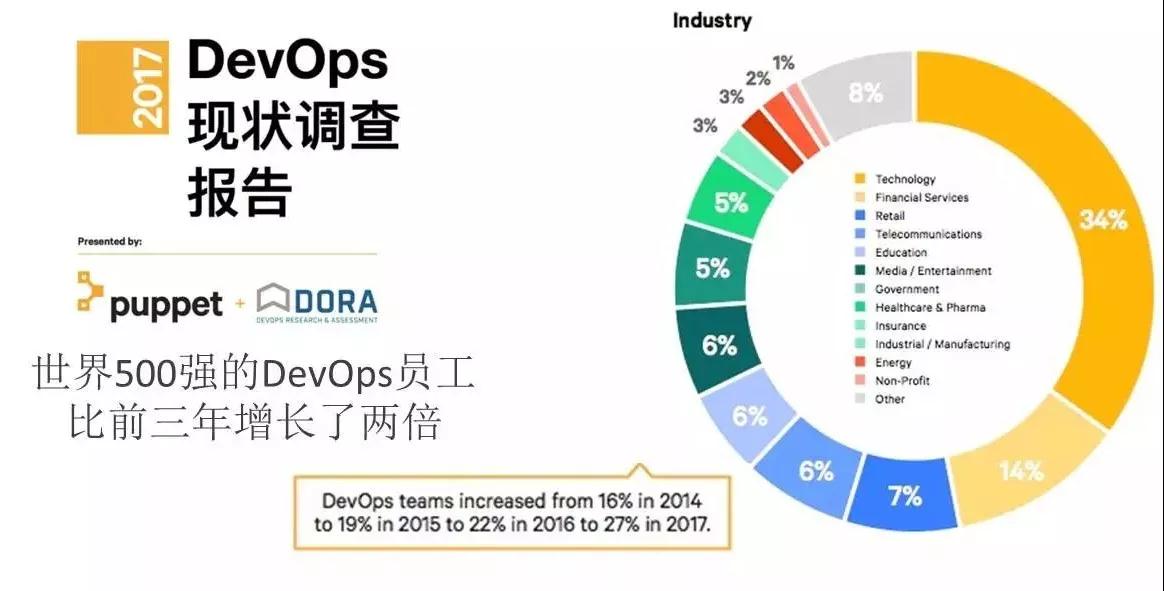
我们看看 DevOps 的发展状况,通过每年的 DevOps 现状调查报告,我发现了一个比较有意思的现象:就是前三年,公司内部叫 DevOps 工程师的员工数量增长了两倍,现在很多公司有专门的 DevOps 工程师,做创业的人都知道,之前你要找一个技术团队肯定是先找开发,再找运维,第三个再找 DevOps,但现在很多硅谷公司,他们是 DevOps 和开发一起找,因为 DevOps 工程师可以用很多较超前的工具做快速的发布。
DevOps 的收益
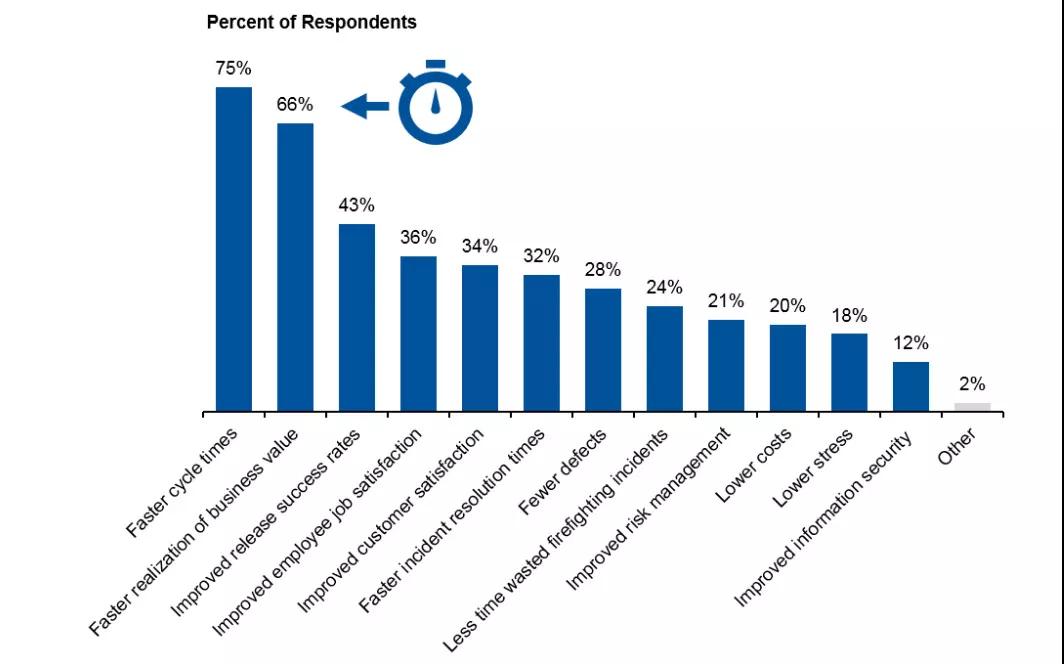
关于 DevOps 的收益,我们都知道,一键发布可以提高我们的软件交付速度,也叫做快速发布,但快速发布依赖于很高的自动化测试能力,自动化测试可以提高软件软件交付质量。但自动化测试工具和用例多了之后,测试的时间开始变长,开发需要等待时间很长,如果最后一步失败,这会浪费很多等待的时间,所有需要让失败的 case 在早期失败(Fail Fast),将下游的测试用例补充到上游测试用例,可从而避免在最后一步失败的问题。
DevOps 全球开发者分布
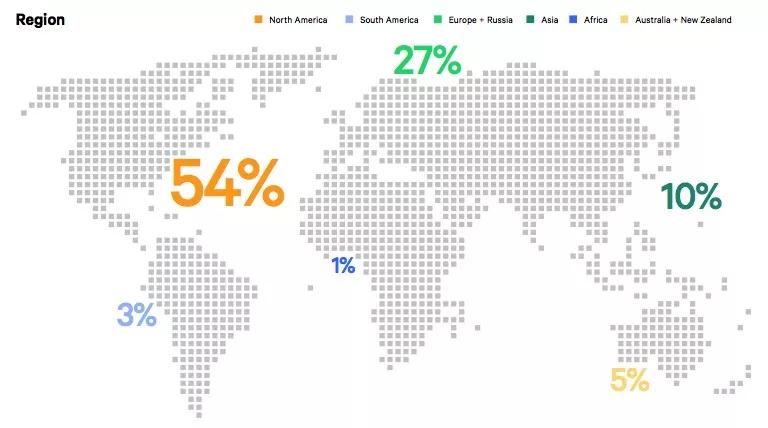
我们看一下全球在做 DevOps 的公司分布。从上图可以看出一个很大的问题,就是亚洲明明有很高的消费能力,有很多智能手机的用户,但全球的 DevOps 工程师数量亚洲只占了 10%,而欧洲和美国却占有全球最大的一部分,为什么?这也是我此次分享的一个目的,我希望大家都可以多做一些交流,多对外分享各自内部的 DevOps 实践。在欧洲,很多大的银行、保险公司都会分享他们内部的一些实践:怎么用亚马逊或公有云,用了哪些工具,如今中国国内也有越来越多的公司在分享,但也还比较局限于国内地区,我们需要扩大影响力。
全球最超前做 DevOps 的公司

全球范围内哪些公司做 DevOps 最超前?我们这边有一些案例,谷歌云每周 20 亿次变更,都是用 Kubernetes;我们认为 Netflix 是最超前做 DevOps 的公司,大家可能有看过《纸牌屋》,一个比较敏感的美剧,但 Netflix 不仅是拍美剧了,还占有全国 60% 的带宽,很多人坐沙发上看电影,在国外都是用 Netflix。
还有甲骨文和思科,他们都做了一个一站式交付平台,封装了 Jenkins、JFrog、Sonar 等测试工具去做统一的测试与部署,他们是属于大规模的 DevOps。国内的腾讯和阿里,腾讯至少有两个团队在做相关的事情,一个是在做集中式的 DevOps 平台,另一个是负责蓝鲸,蓝鲸是一个非常强大的自动化运维工具平台。阿里巴巴在杭州有一个团队在打造阿里内部的平台 - AOne,阿里的很多业务已经迁移到他们的平台上去做一站式的测试和部署。还有华为,我们知道至少有两个团队在做公司内部的 DevOps 交付平台,这也是特别超前的,做得效果也很不错。
这些公司是怎么做 DevOps 的?
下面是今天分享的重点,主要跟大家分享一些上述这些公司是如何超前地做 DevOps,他们用了哪些工具,怎么评估团队,怎么说服领导,如何做一个自助式的 DevOps 平台 。
第一,自助式 DevOps
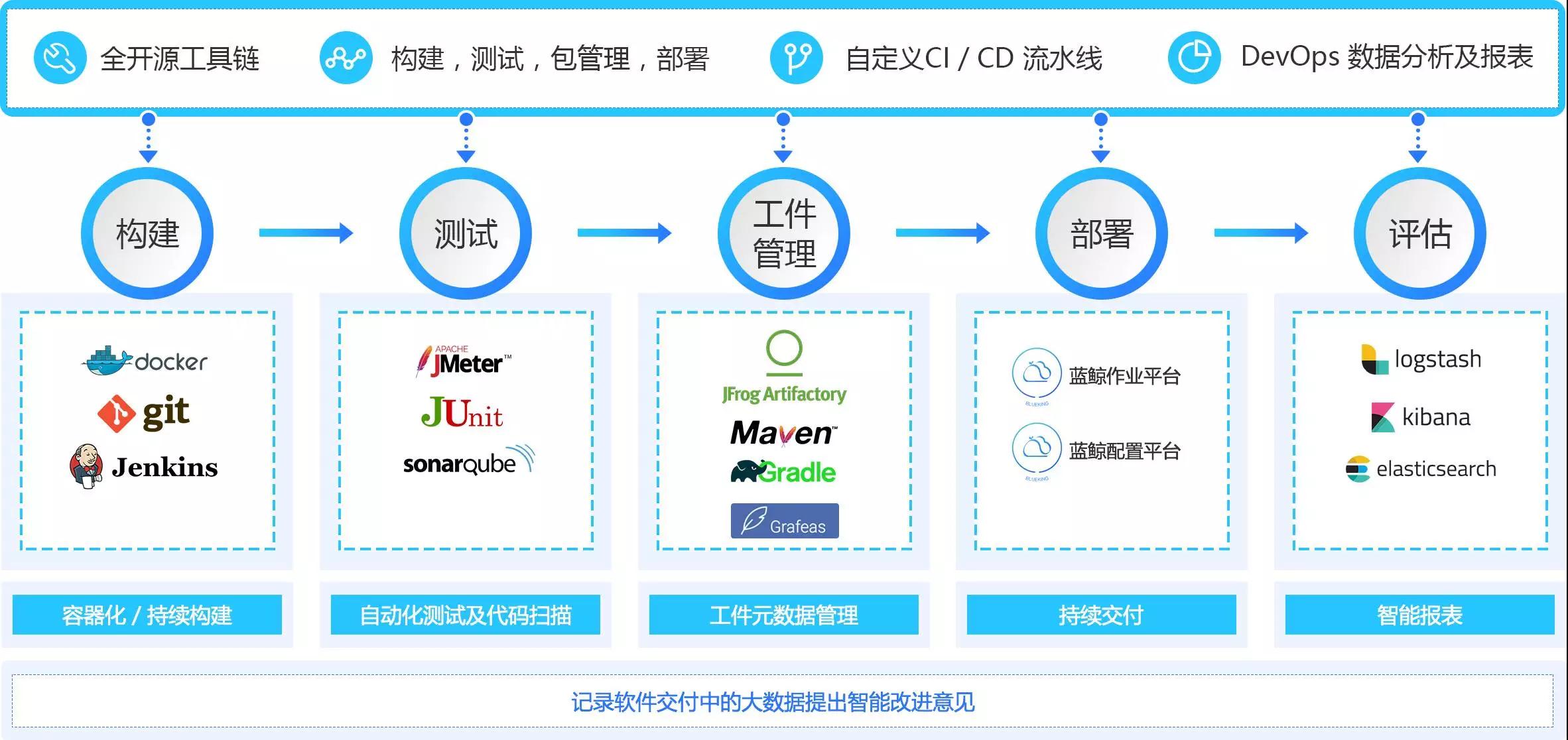
就是在每个阶段要评估最好的工具,这里以腾讯为例,腾讯在前面做构建时,大部分是用 Git,然后用 Jenkins 去构建,用容器的环境去跑构建的任务,比如说一个 Jenkins 任务跑到一个容器里面,构建完了,就可以很好地收集一些资源。而测试工具,值得一提的是 SonarCube。SonarCube 做单码扫描,它也是被用得比较多,像滴滴、百度、阿里等这些大互联网公司都在用。中间工件管理部分也是比较关键的,包括你的数据管理在每个阶段从提交代码一直到构建、测试,发布到什么环境,都是存在一个地方,所有的数据和包都是存在 JFrog Artifactory 里面,都要通过各自公司内部的标准区做流水线。最后部署和评估,很多公司在评估他们的 DevOps 数据,这个月和上个月底相比,发布到底有没有变得更加高效,我的测试突破率有没有比之前快。上图中提到的是我们评估用得最多的一些工具,当然每个阶段还有更多别的工具。
第二,自定义流水线
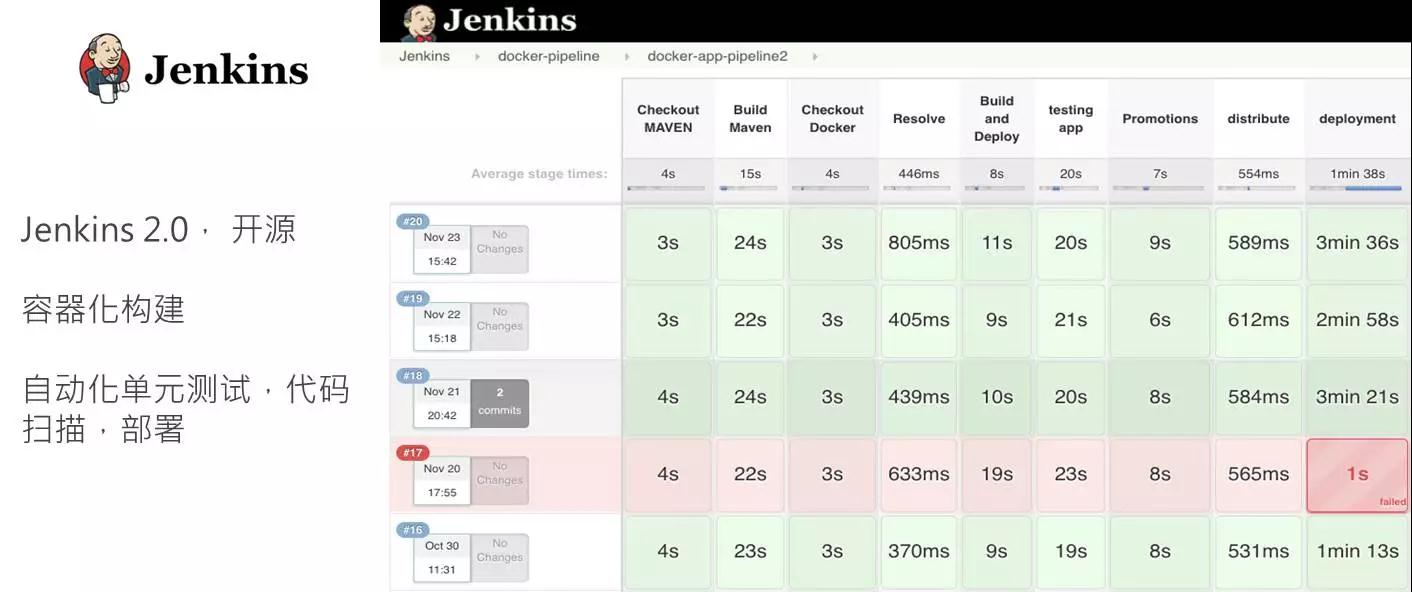
不知道在座的有没用到 Jenkins 2.0Pipeline 插件,现在 Jenkins 创始人 KK 在每个大会上都会讲他的 Pipeline 插件概念,去年我参加了他在以色列的 Jenkins 大会,他在会上就发布了 Pipeline 插件。但不管是用 Jenkins 或者别的工具,都要把一些可重复使用的阶段,比如测试、部署放在一个模块化的 CI 流水线里面, 开发者就可以自己上线,自己发布。现在一些大企业的团队就是自己上线、自己发布,他们采取微服务架构,不设定有变更日,随时都可以独立发布自己的模块,不用要协同所有模块一起。大家可以尝试 Jenkins Pipeline 这个插件,是开源免费的。
在我们这个例子里面,做 Maven 构建,然后搭建一个镜像,用镜像做一些测试,部署到测试环境里,那么做完各种自动化测试之后,就可以部署到生产环境。一些金融公司是要有一个员工审核的过程,也可以放在开发里面,开发可以发邮件、发短信等。
记录生命周期元数据
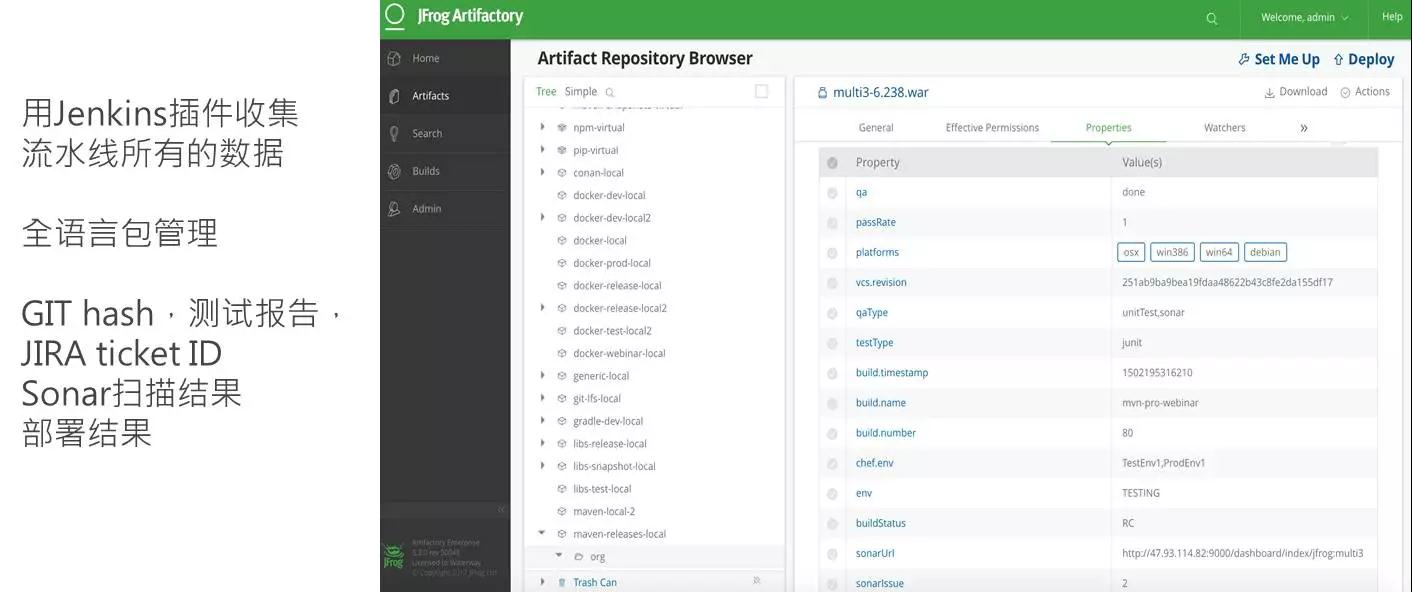
这个过程会产生很多数据,每一步关键的数据都需要存在统一的地方,叫元数据。Jenkins 和 JFrog 目前世界五百强里面大部分的企业都在用,JFrog 有一个插件在 Jenkins 里面,安装之后,在构建时就可以把你的测试通过率,还有 SonarCube 的地址、部署的结果,以及你当时部署了什么机器,都跟构建包进行绑定,所以现在你公司内部所有的工件,不管是什么语言(可以看到图中左手边各个语言的包),都要根据 DevOps 团队的一个规范和标准去上线,如果这个包没有所有的元数据,没有所有的测试结果,而且没有这个 QA,这个包就不能上线。这就等于在公司内部设置了一个质量关卡, 从开发、构建、测试到部署所有阶段的关键信息都是要放在一个地方才能实现流程的决策自动化。
制定软件交付质量关卡

质量关卡是一个比较老的概念,Jenkins 和 JFrog 是怎么参与到这个过程中的呢?答案是用自动化测试供,通过把测试结果和这个包绑定,如果想要把发布的包从开发环境升级到测试环境,再到部署环境,必须得收集到特定的元数据才可以到下一个阶段,这个叫质量关卡,很多大企业现在就是用的这个标准,即如果我的 Released 包没有具备所有的测试信息,流水线不会让它到部署到我的生产环境,这个主要是去保证软件的质量,正如之前讲的“快速失败”,如果把一些自动化测试、继承测试放在一个早一点的阶段,就可以避免浪费很多的时间。
第三,智能查询
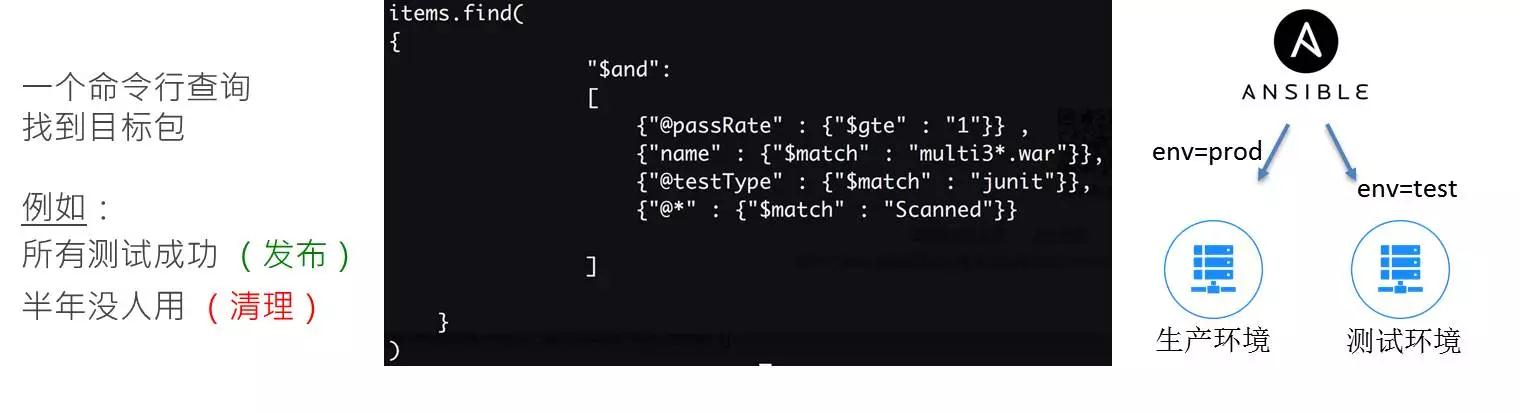
最后,你需要一个智能的查询能力,去找到公司内部的好几万个包,像思科、华为都有几十亿个包,不是最新的版本,而是经过测试且单元测试通过率为 100%、漏洞扫描已经通过的包,可以自动地将它部署到生产环境。像思科、甲骨文他们会做一些自动的清理,比如说有一个包在半年之内没有被下载,它会自动去做删除,所以如果你们存储的成本越来越高,也肯定要评估怎么做一次自动化的清理。同样是做一个环节再做下一个环节,所以可以用 AQL 这样一个工具去做,很多大企业也是这么实现的。
全球 DevOps 标准
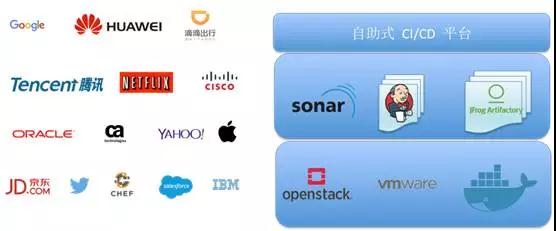
现在国内外都有一个非常大的趋势,就是说公司到了一定的规模,都要开始封装自己的 DevOps 平台,不然很难让一个小而传统的团队去上持续自动化交付,通常我们需要花钱找一个敏捷教练在公司里面讲 PPT,让他们快速用这个工具。互联网公司的做法是自己封装一个 DevOps 平台,对接底层工具平台,比如 Sonar、K8S、Jenkins,实现统一的资源申请,这样的好处是每个团队的交付流程一致,能够在公司内部实现持续交付的标准,研发团队也不用维护底层的各种工具链。
1.Netflix

第一个例子是 Netflix。Netflix 在开源社区是一个非常大的贡献者,他们开发了很多开源工具去做部署、打包等各种功能。 其中有一个做混合云环境部署的工具叫 Spinnaker,Spinnaker 是 Netflix 在的一个开源的项目,能够实现跨云平台的部署任务的编排。现在 Netflix 使用 Spinnaker 每天发布 4000 次变更到亚马逊的机器上。谷歌云也在用 Spinnaker 去做部署。他们构建时也是用 Jenkins,其中有一个过程叫 bake,bake 是把应用打包成一个镜像,然后把这个镜像用 deploy 去做部署。Netflix 的 DevOps 实践非常值得关注,他们也有很多项目和开源工具都值得一看。
2.Oracle

第二个例子是甲骨文,我们都知道甲骨文是做数据库的,但它同时也是一个非常大型企业级软件公司,他们现在是 4 万开发者的规模,之前有很多传统的应用,也有非常大的部署。甲骨文内部也有很丰富的容器云实践经验,到去年年底,他们每天有 150 万次 Docker 并发请求,这是比较酷的。
复杂交付流水线
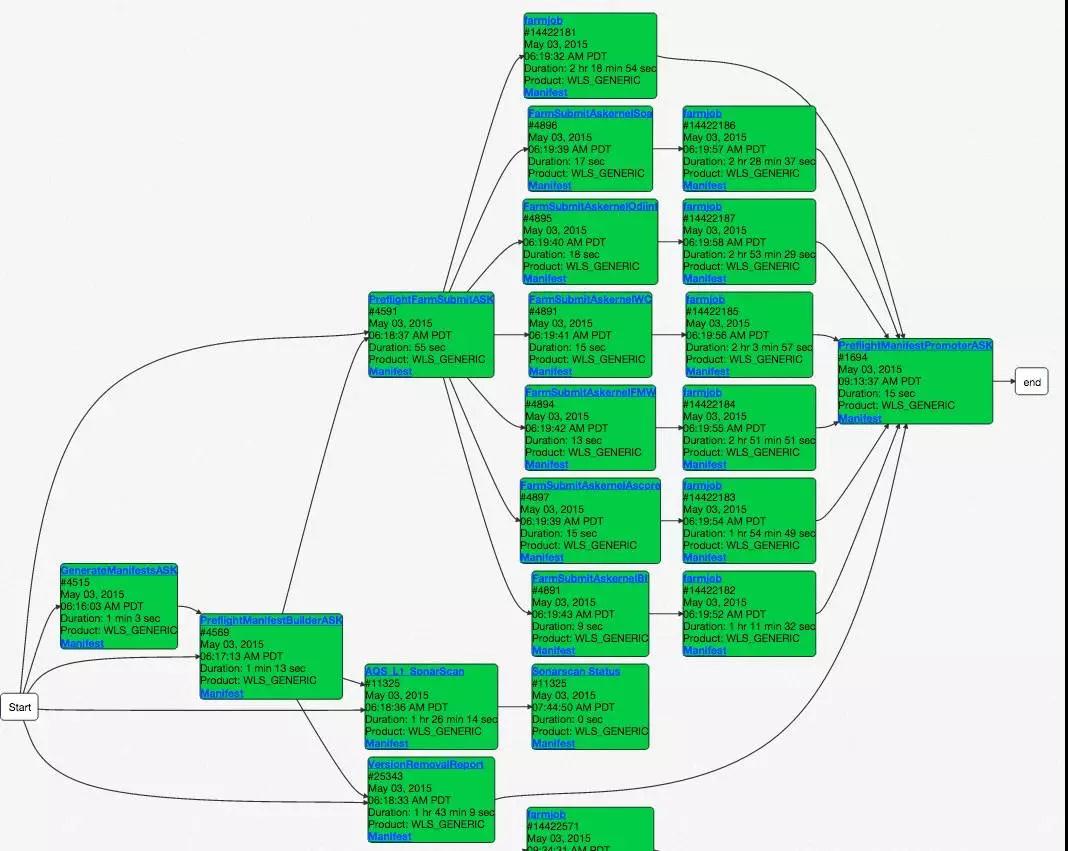
这是甲骨文之前一个很大的痛点,他们的流水线非常复杂,有很多并发的任务,特别是他们的测试方案,要花很多的时间,比如说某一个任务需要两个多小时去做,如果现在每个开发者都提交代码,都在位置上等两三个小时,然后再把 4 万开发者乘以两个小时,这样算下来一年要多少钱?所以肯定要开始优化这个过程,因此他们需要一个可视化的工具,去知道哪个步骤是最好的时间,然后去看哪一步、哪一个任务怎么优化,是不是要做一些性能测试的优化。
多语言 DevOps

甲骨文自己内部做了一个持续交付平台,是封装的 JFrog、Jenkins,这个团队最开始是只有中间件一个小团队,他们也是遇到其它公司普遍遇到的问题——怎么说服领导。他们是先有一个小团队,进而做这种实施的评估,看这个团队的效率有没有什么变化,比如说上线的速度有没有变得快、测试通过率有没有变化,然后在公司内部出了一个报告,显示中间件团队用了 DevOps 平台上之后效率的情况如何。
于是,他们在一年之内把这个数据库的团队和甲骨文其它的团队迁移到了 DevOps 平台上,因为他们都发现做同一持续交付平台的好处是很明显的,那么从 2015 年开始,这个平台通过 API 的方式可以去支持任何开发工具、开发语言,就是最开始讲的一个很关键的事情,如果要做公司内部的平台,未来肯定要扩容。就像我现在虽然只有 Java 开发,但将来我们收购了一个小公司,他们用的是别的语言,我必须能够变得能够支持别的语言。
可视化流水线

这是平台自定义作业编排的界面,你可以按需编排任务,通过消息触发每个阶段容器化的构建、测试。
报表及统计

甲骨文最强大的事情就是跨团队的报表评估,他们可以查看每一个跑了多少次,里面有多少次成功,多少次失败。里面所有复杂的任务,他们都可以进行时间的评估。也有可视化的工具,不用派几个人,周末加班,给领导做一个报告或 Excel,现在有自动化的页面可以给领导看,这是非常重要的事情,即使不太懂底层技术的人,也可以上线看团队的一些效率方面的评估报告。
DevOps**** 平台内部扩容
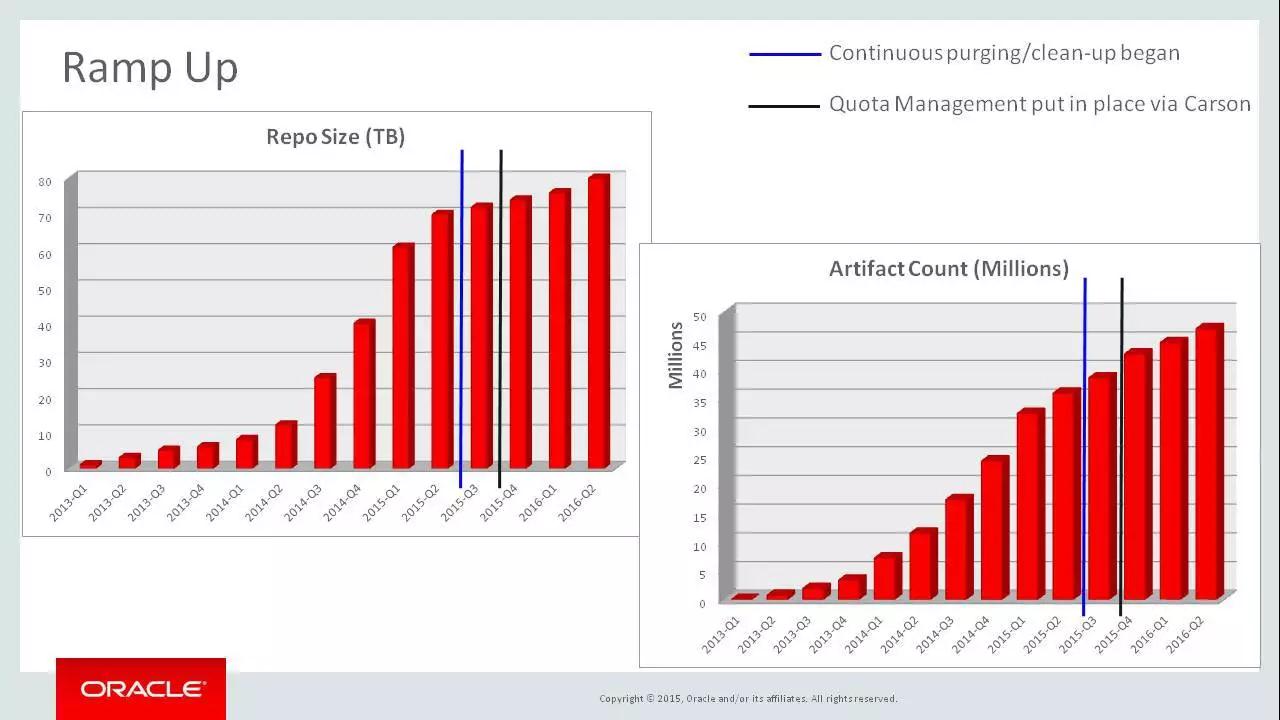
甲骨文是 JFrog Artifactory 的早期用户,在 2013 年 -2015 年间,他们某一个研发中心某一个仓库的数据,一年半之内从 17TB 涨到了 70 多 TB,这还只是其中一个研发中心(甲骨文有 6 个研发中心),当数据达到 70 多 TB 时,他们开始做一些自动化的删除,前面也讲过了一个规范,如果包在半年之内没有被用到、没有被下载,这个包就会被删掉,都会用这个去做。
3.ING
第三个例子是 ING。ING 是全球金融巨头,虽然中国的银行在全球十大银行里面占了 6 个,但 ING 在国外算是比较大规模的了,去年超过 1000 亿收入的规模,也有全球的研发中心。现在他们要面对国内很多金融公司要面对的事情,就是怎么从传统的开发模式变成一个超前的 DevOps 模式。
ING**** 持续集成
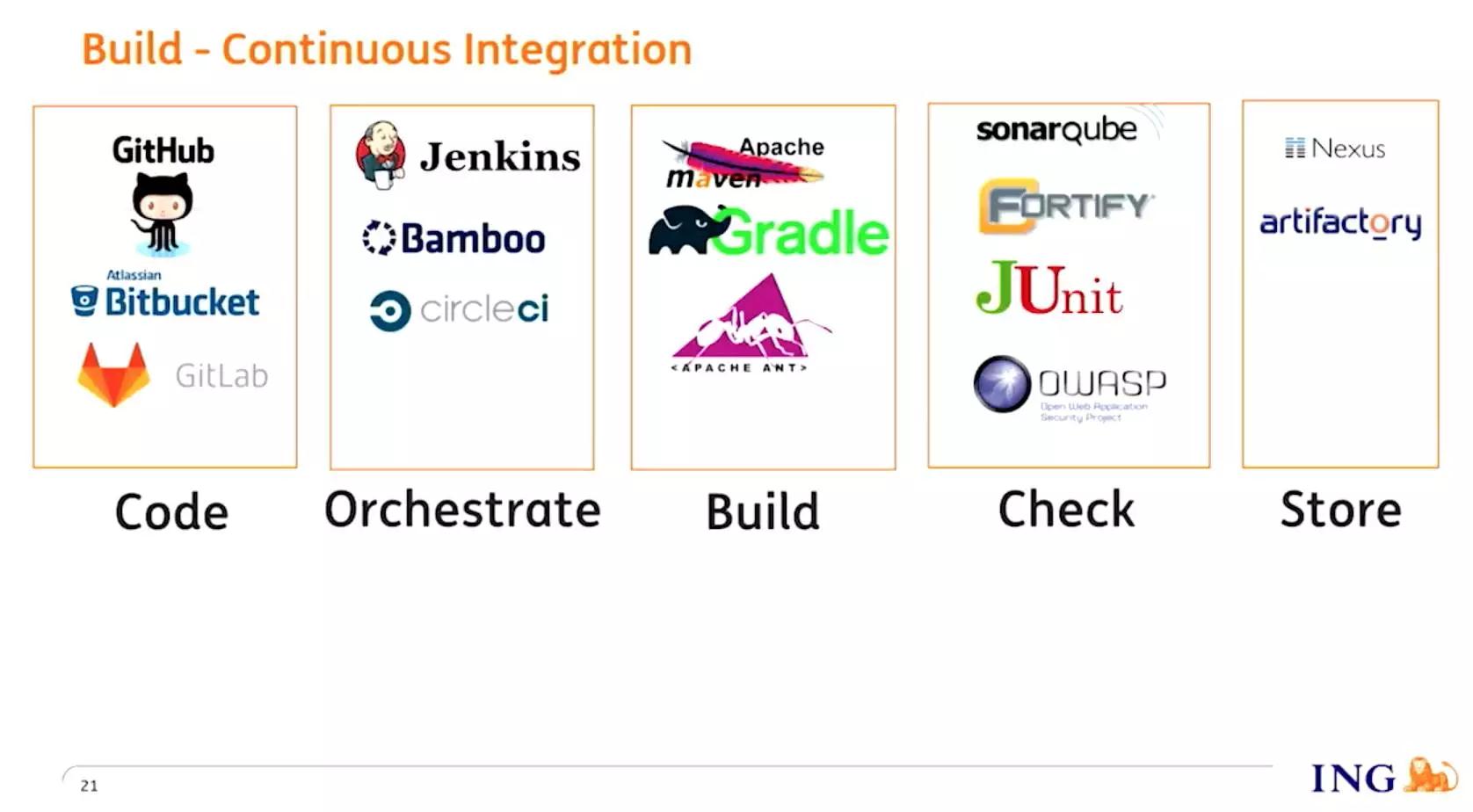
之前 ING 公司 IT 部门有 1000 多个团队,每个团队都有自己的上线流程,每个团队都在重复踩坑,开发重复的功能来支持上线。所以 ING 为公司所有 IT 部门搭建了统一持续交付流水线,让公司所有团队都受益,也叫作”CDaaS”,提供端到端的上线服务。
ING**** 持续交付
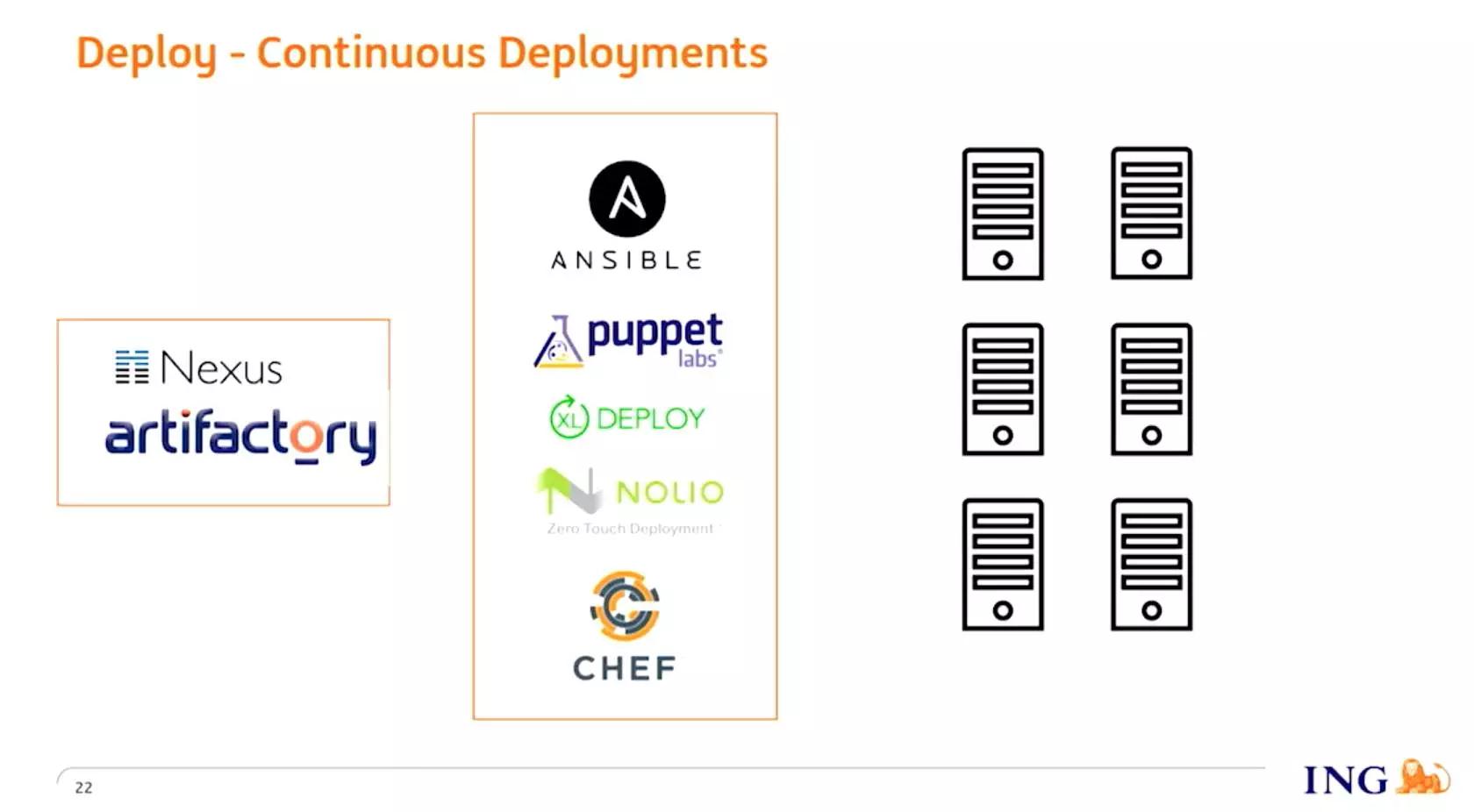
部署工具支持 Ansible、Puppet、XL Deploy、Nolio、Chef 等多种部署工具,这些工具在分发包之前都从 JFrog Artifactory 去获取包的对应版本。
ING**** 多语言开发

部署的话,他们也能部署到多个工具,比如 Artifactory,因为不同的研发中心,不同的团队,不同的工具都要去做部署。所以这个平台得非常灵活,能够支持很多团队的工作。他们也是多元的,有 Maven、Docker、NPM 等,他们都要开始管理。
ING**** 自定义流水线
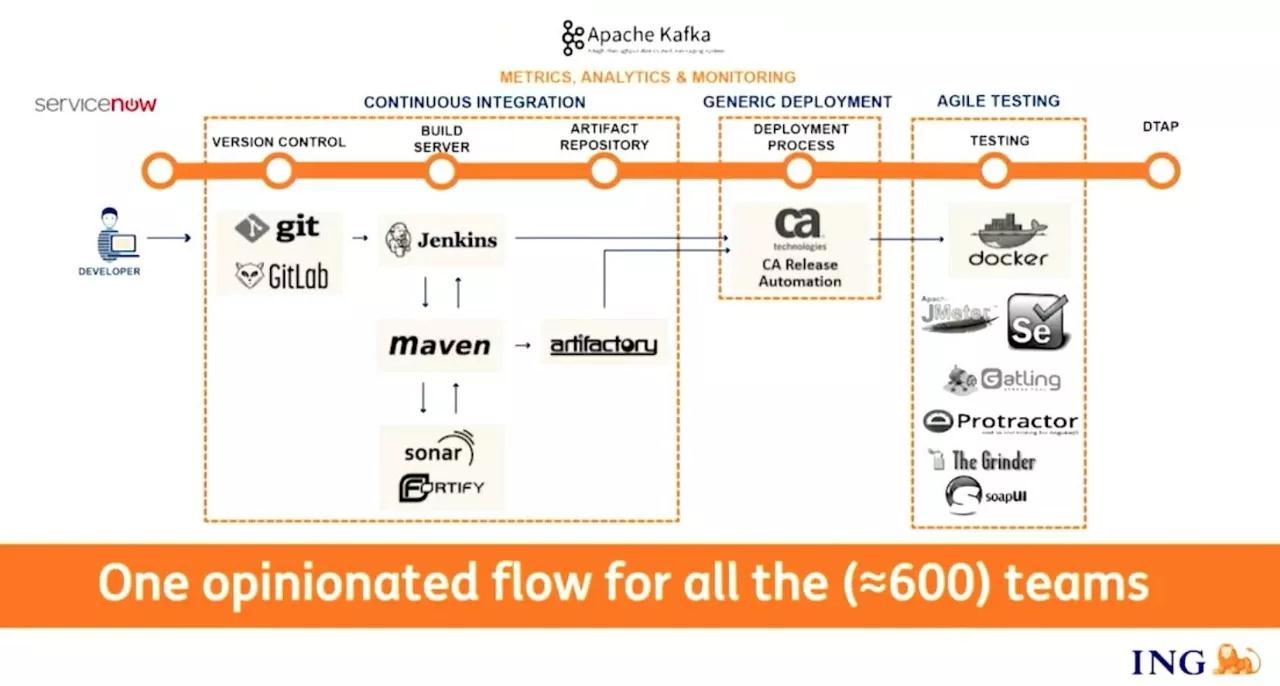
他们的目的是最终实现 600 个团队的支持,一个自定义的流水线,从拉源码开始,然后做一些测试,把包放到 Artifactory,他们用一些付费的工具去做部署,测试也很多跑在 Docker 容器里面。ING 提供的统一交付平台对接了很多工具,覆盖了代码管理、构建管理、工件管理、部署管理、环境管理等上线所需的功能,为 ING 的内部 IT 团队提供了可靠的交付流水线。
ING**** 高可用容灾
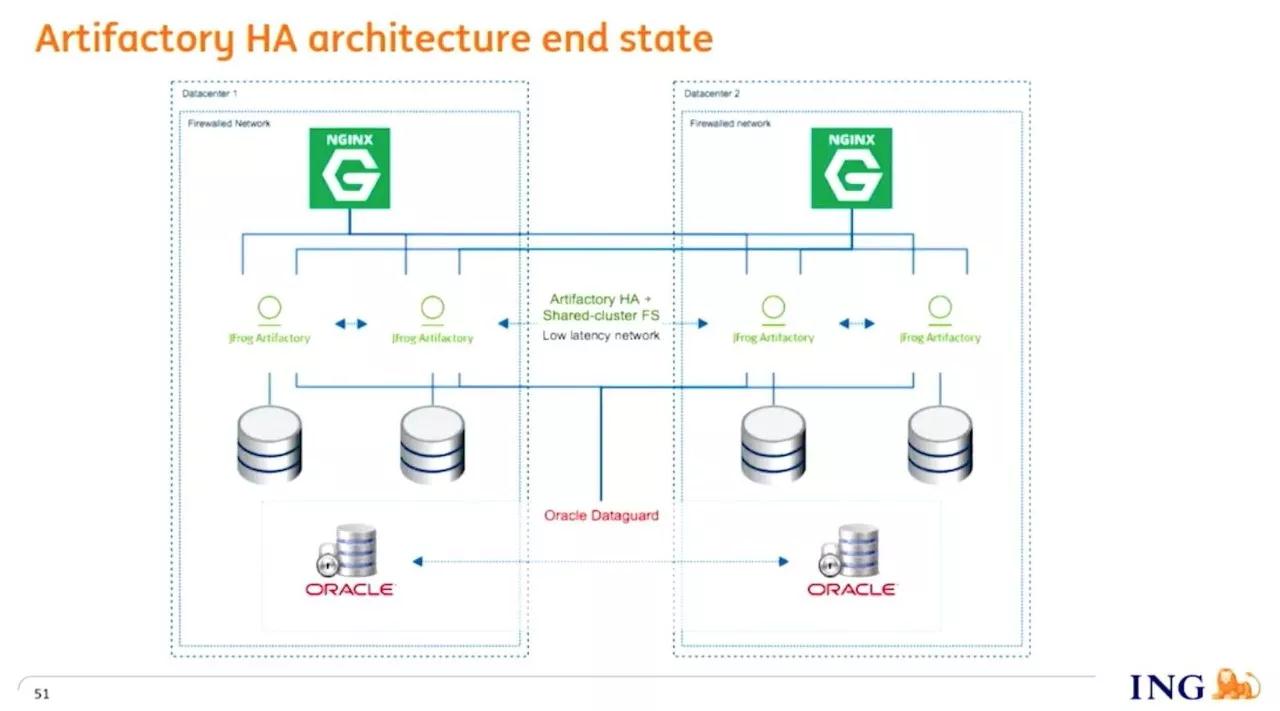
金融行业比较关注的是高可用的容灾,这些包肯定要用容灾的,那么可以做高可用的包管理,也可以用多个节点去做分流。例如华为,在深圳有七个 Artifactory 的节点,因为他们要进行几万开发团队的并行上传、下载,是非常高的并发构建。
4.思科
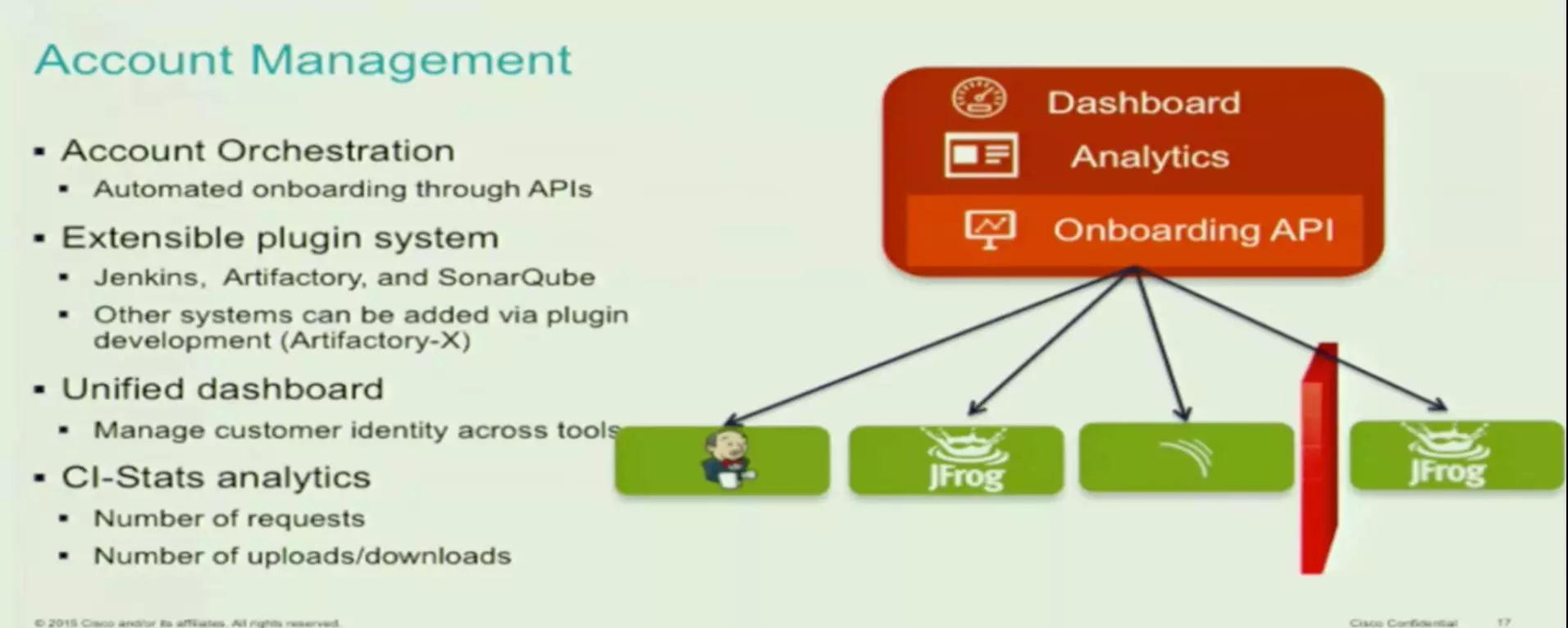
最后介绍下思科,思科的平台叫 Account Management,他们有一个 5 人团队,做了一个平台,可支持全公司 3 万开发者,同时也是全球多地开发的。Account Management 是封装 Jenkins、JFrog,从图中可以发现基本上是一样的工具。Account Management 通过给团队一个页面,去申请一个 Jenkins 容器,申请 JFrog 的资源外包,都在 Account Management 里。

从这里我们可以看到,创建一个新的 Service 非常简单,你不用关注底层的 Jenkins 配置,不用关注包管理系统,只需要在一个页面上去申请。
全球 DevOps
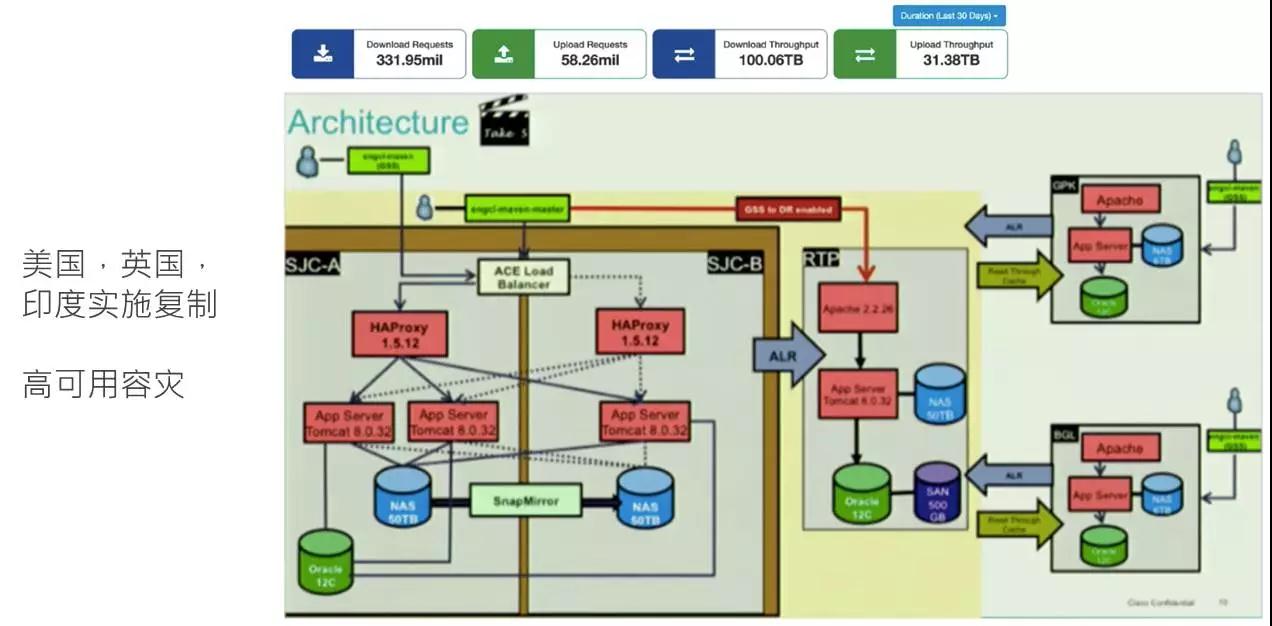
它们也有全球的包复制方案,他们在美国的硅谷有一个高可用的容灾,英国和印度都要做实时复制,比如说他们的某一个包是在硅谷构建,但要复制到印度去做测试,这就需要有实时复制的能力,这里都是用高可用容灾去做实时复制。
元数据
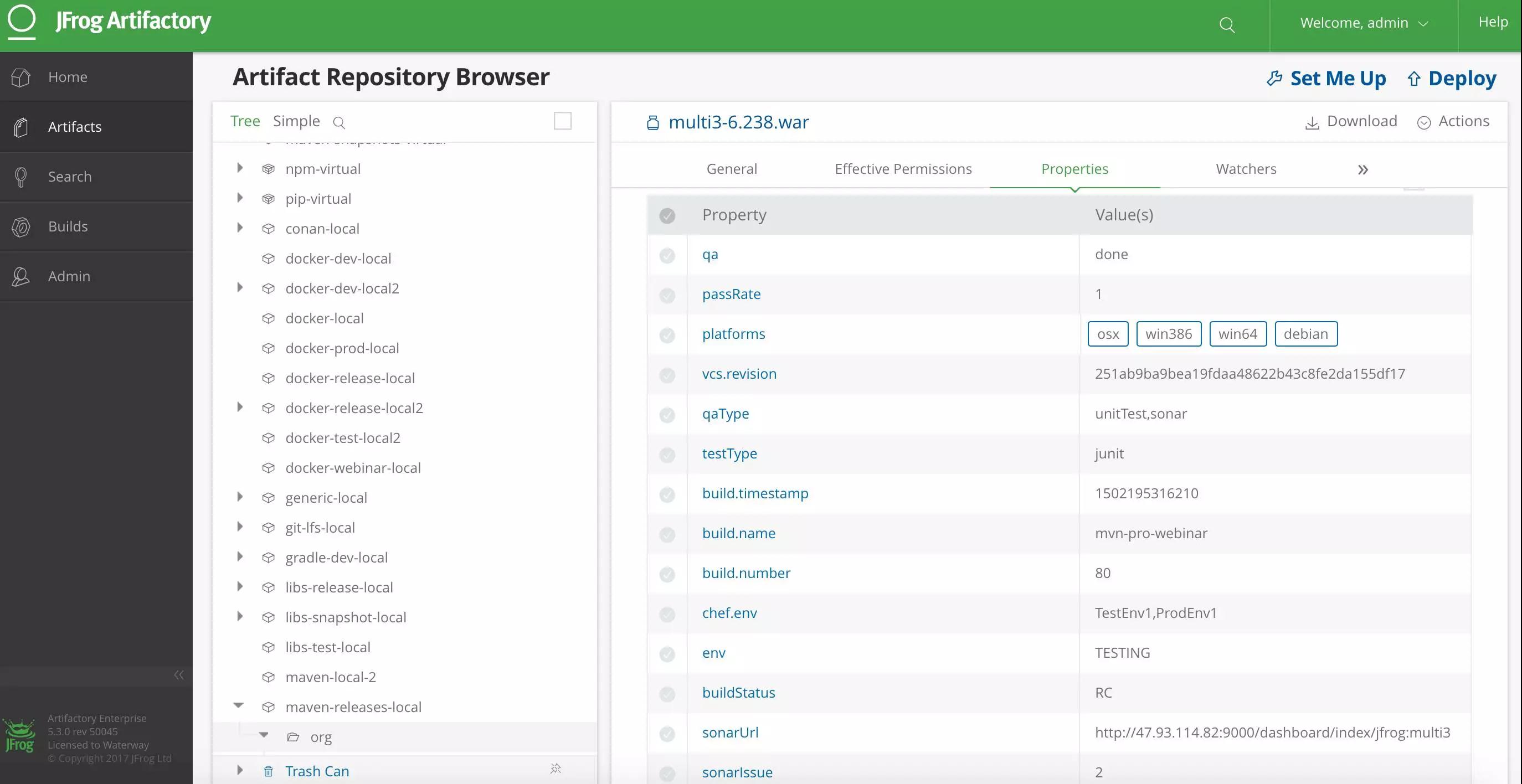
之前那个例子就是把思科每个包绑定很多的数据,测试报告、测试类型、QA 的状态,所有的都要在一个地方去管理。
5.JFrog 杰蛙

最后跟大家介绍下 JFrog 的平台(官网:JFrogchina.com)。JFrog 是作为一个全语言的管理系统,统一管理外网的依赖包和公司内部构建的包,并且提供企业级高可用,它可以跟 Jenkins 对接,能够分析这次构建涉及到的外网的包是否存在漏洞,也能做元数据收集,跟测试工具集成,将测试数据跟包做绑定,并将应用部署到虚拟机或者容器环境的信息回写到 Artifactory,作为元数据与包进行绑定。
我们还有一个平台,提供一站式的快速发布服务。我们今天看很多公司都有一个页面去做整套 DevOps,但这些都不是开源的,也不能快速地落地。我们跟腾讯联合开发了一个应用叫 DevOpsOne(官网:devopsone.cn),对接到蓝鲸做部署,下一步我们要做一个全开源的平台,这个开源的平台就是做甲骨文、思科做过的事情。具体做法是封装这些开发工具链,提供一个统一的平台去做流水线、部署、测试,报表及数据挖掘,全面降低 DevOps 上手的复杂度。

这个架构也是用 Jenkins、Maven、JUnit、Sonar、Docker 容器等工具来做的平台,这是一个免费开源的平台,可以快速实现企业内部的一站式持续交付平台。
未来还要做很多报表,在需求到上线的整个流程中,持续度量团队上线的速度和平均的上线速度,我们都会根据标准进行分析和评估。所有工具都会在一个系统里面去做,从需求、构建、源码、测试到部署都在一个地方去做流水线,包括管理、部署、报表,都是开源、免费的。
最后这是提供流水线的形式,底层就是用 Jenkins Pipeline,用户只需要在 DevOpsOne 上定义自定义的持续交付流水线即可。
Q&A
**Q1:** 关于 DevOps 的问题,您刚才提到国外的很多企业,比如甲骨文、思科他们都是用同样一个 DevOps 平台,大家的开发、部署、业务都是统一一个平台。但我们公司不太一样,我们之前倾向于统一的平台,但这个统一的平台出问题了,所有人都在等,后来我们就拆了,就是说每个团队的运维,这些全部都是自己的团队去负责,你可以选自己的工具,这个工具也是自己维护的,我不知道是统一平台管理所有的东西,还是交给自己的团队去负责整个 DevOps 的东西的做法,哪一种比较正确?
**A1:** 先不说正确与否,从业界的趋势来说,大家做开发,他们所有的团队构建是底层基于一个很庞大的构建系统,包括测试、打包、发布,每个团队维护的成员就是一个很小的团队,每个人上来以后做自己的构建、测试。你刚刚说的问题可能是平台稳定性的问题,这里面还是回到甲骨文这个案例,甲骨文是平台公司内部有 500 个 Jenkins 的 Slave 节点,这 500 个节点都是跑在高可用容器环境里面,让其具备很强的高可用能力,它用这个容器去保证这个节点的高可用,如果宕掉了,它会实时再虚拟出来一个环境,让它接着跑这个任务。这个是容器环境让它具备这种高可用的性能。
它还有一个好处,我的资源就这么多,当每个团队都来申请,势必出现资源紧缺、排队的情况,所以容器的好处是我用完以后,测试完以后,我自然就释放了。但我把这个构建产出物,上传到我这里,把每一步执行的测试元数据记在这个包上面,再走到下一步,通过这种方式去给每个团队提供统一的流水线。
**Q2:** 想问关于自动化测试这一方面的,刚才介绍了很多工具,我们公司目前现状是上线之前会有测试组,人工来测,关于 DevOps 自动化这一套测试有什么好的建议?
**A1:** 从测试角度来看,其实如果有在外企、国企或者是国内民营企业待过的,可能会发现有一些明显的不同。外企的研发团队对这个测试的覆盖率、自动化率相对来说会高一些,国内由于业务上线的压力,我先上了,实现功能了,再来补这个测试用例,但最后发生一个什么问题呢?上线交付周期越短,没有那么快的时候还好,如果交付频率变快,那你的测试团队会变成瓶颈。
之前我们和亚马逊 Kindle 团队的测试负责人聊过,他们就用这个 Kindle 做完全自动化的 UI 测试,他们用一个工具叫做 APPIUM,专门做这种模拟屏幕的点击,完全百分之百的案例覆盖,他们杜绝一切人工的模拟屏幕的点击,虽然这个投入很大,但在一年半载之后会产生很大的收益。同时你的测试团队会从一个点击的角色,人工测试的角色变成一个开发团队。亚马逊全公司都是自动化测试,没有员工手动测试的概念,雅虎也是,这两个公司测试做得非常好。
**Q3:** 你们有没有计划跟云厂商合作,会不会考虑这种资源会更节省的方案?因为其实我们如果一个很大新的项目,需要很多 Artifactory 实例,想了解一下你们这边的情况。
**A3:** 本身 JFrog 也有一个公有云版本,目前支持在亚马逊和谷歌云、微软云上部署。如果是部署到亚马逊,也有一个工具。如果你已经是亚马逊的用户了,可以在亚马逊上建一个帐号,你不用维护任何的 Artifactory 机器即可使用,按照用量、存储量计费,用量会比你实际存储还要少一些。