
1000 万 PPS 120 万 IOPS,UCloud 快杰云主机的技术进阶之路
自 UCloud 在 5 月 28 日的 TIC 大会上发布“快杰”云主机后,已经过去了近半年的时间,在这半年间,“快杰”凭借优越的性能与极高的性价比,在云主机市场中走出了自己的独特道路。在这些成果背后,我们用两个词来阐述“快杰”的技术理念:All in one & One for all。

All in one & One for all
作为云计算的基石产品,云主机的核心特性决定了云上其它能力的拓展,也直接关乎于用户的使用体验。用户选择云计算的出发点在于:简单性,速度和经济性。但是由于互联网与 IT 服务的场景多样化,业内大多数厂商都是分别推出适应不同场景的云主机类型,但也因此带给了用户运维和采购的复杂度。
什么是“All in one”呢?“快杰”将自己定义为“简单”的产品。简单不仅意味着使用方便,还意味着多项软硬件技术的融合,以此为用户提供超高的产品性能。也就是说,当你面对各种业务场景下 CPU、网络、存储的不同性能需求时,无需考虑太多因素,“快杰”均可满足。
这是“快杰”的一组数据:全面搭载 Intel 最新一代 Cascade Lake 处理器,配备 25G 基础网络并采用全新的网络增强 2. 0 方案,支持 RDMA-SSD 云盘,网络性能最高可达 1000 万 PPS,存储性能最高可达 120 万 IOPS。
在产品上线之初,我们对“快杰”进行了跑分测试,测试结果显示,同等规格的配置下,“快杰”的性能明显优于市场上同类型的云主机产品。举个例子,在同样 8 核 16G 的配置下,“快杰”的网络性能较友商高出 3 倍多,存储性能有着近 4 倍的差异。
但是在这样的高配下,“快杰”的价格提升却不超过 20%,部分配置机型的价格与普通机型价格基本持平或略有下降,云盘价格仅为市场同类产品的 60% 或者更低。“快杰”云主机用“One for all”的价格红利将所有技术又通通回馈给了用户。
“罗马不是一天建成的”,不论是 All in one 还是 One for all,在这些数据的背后,都离不开 UCloud 在技术上的持续探索和积累。接下来,我们就来聊聊“快杰”背后的技术进阶之路。
一、 网络增强 2.0: 4 倍性能提升 + 3 倍时延下降
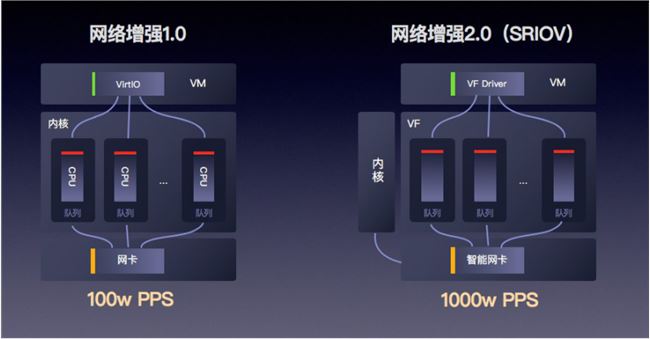
网络通道是严重制约云主机性能的瓶颈之一,在这里,值得一提的便是“快杰”在 25G 智能网卡网络增强能力方面做出的技术突破。
■ 硬件级别的网卡加速
基于云主机网络性能提升的需求,25G 网络逐渐成为趋势。但是由于传统软件 Virtual Switch 方案的性能瓶颈:当物理网卡接收报文后,是按照转发逻辑发送给 VHost 线程,VHost 再传递给虚拟机,因此 VHost 的处理能力就成为了影响虚拟机网络性能的关键。
在调研了业界主流的智能网卡方案之后,我们最终采用了基于 Tc Flower Offload 的 OpenvSwitch 开源方案,为“快杰”提供了硬件级别的网卡加速。虚拟机网卡可直接卸载到硬件,绕过宿主机内核,实现虚拟机到网卡的直接数据访问。相较于传统方案,新的智能网卡方案在整个 Switch 的转发性能为小包 24Mpps,单 VF 的接收性能达 15Mpps,使得网卡整体性能提升 10 倍以上,应用在云主机上,使得“快杰”的网络能力提升至少 4 倍,时延降低 3 倍。
■ 技术难点突破:虚拟机的热迁移
在该方案落地之时,我们遇到了一个技术难题:虚拟机的热迁移。因为各个厂商的 SmartNIC 都是基于 VF passthrough 的方案,而 VF 的不可迁移性为虚拟机迁移带来了困难,在此将我们的解决方案分享给大家。
我们发现,用户不需要手工设置 bonding 操作或者制作特定的镜像,可以妥善的解决用户介入的问题。受此启发,我们采用了 VF+standby Virtio-net 的方式进行虚拟机的迁移。具体迁移过程为:
1、创建虚拟机自带 Virtio-net 网卡,随后在 Host 上选择一个 VF 作为一个 Hostdev 的网卡,设置和 Virtio-net 网卡一样的 MAC 地址,attach 到虚拟机里面,这样虚拟机就会对 Virtio-net 和 VF 网卡自动形成类似 bonding 的功能,此时,在 Host 上对于虚拟机就有两个网络 Data Plane;
2、Virtio-net backend 的 tap device 在虚拟机启动时自动加入到 Host 的 OpenvSwitch bridge 上,当虚拟机网卡进行切换的时候 datapath 也需要进行切换。VF attach 到虚拟机后,在 OpenvSwitch bridge 上将 VF_repr 置换掉 tap device;
除此以外,UCloud 针对 25G 智能网卡的其他技术创新可查看:https://mp.weixin.qq.com/s/FUWklPXcRJXWdrWpsQHzrg
二、RDMA-SSD 云盘:提供 120 万 IOPS 存储能力
在云盘优化方面,我们主要从 IO 接入层性能优化、RDMA 网络加速及后端存储节点提升三方面来完成 RDMA-SSD 云盘的技术实现,最终为“快杰”提供 120 万 IOPS 的存储能力。
■ 基于 SPDK 的 IO 接入层性能优化
如下图,为传统的 OEMU Virtio 方案示意,在第 3 步时, QEMU 里的驱动层通过 Gate 监听的 Unix domain socket 的转发 IO 请求时,存在额外的拷贝开销,因此成为 IO 接入层的性能瓶颈。
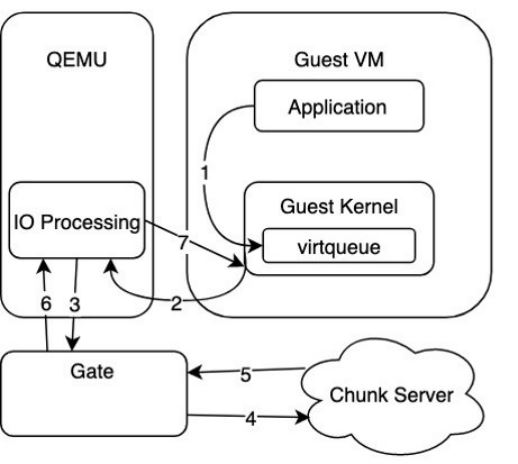
图:QEMU Virtio 方案示意
针对该问题,UCloud 使用了 SPDK VHost 来优化虚拟化 IO 路径。
(1)SPDK VHost:实现转发 IO 请求的零拷贝开销
SPDK(Storage Performance Development Kit ) 提供了一组用于编写高性能、可伸缩、用户态存储应用程序的工具和库,基本组成分为用户态、轮询、异步、无锁 NVMe 驱动,提供了从用户空间应用程序直接访问 SSD 的零拷贝、高度并行的访问。
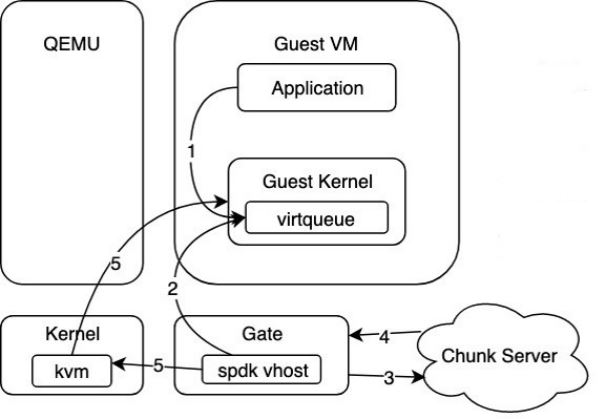
图:SPDK VHost 方案
如上图,在应用 SPDK VHost 方案后,IO 路径流程如下:1、提交 IO 到 virtqueue;2、轮询 virtqueue,处理新到来的 IO;3-4、后端存储集群处理来自 Gate 的 IO 请求;5、通过 irqfd 通知 Guest IO 完成。
最终 SPDK VHost 通过共享大页内存的方式使得 IO 请求可以在两者之间快速传递这个过程中不需要做内存拷贝,完全是指针的传递,因此极大提升了 IO 路径的性能。
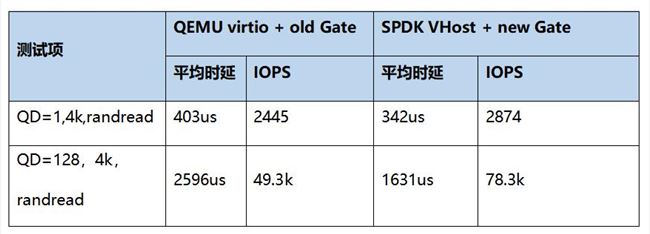
如下表,我们对新老 Gate 的性能做了测试对比。可以看到,在应用 SPDK VHost 以后,时延和 IOPS 得到了显著优化,时延降低 61us,IOPS 提升 58%。
(2)开源技术难点攻破:SPDK 热升级
在我们使用 SPDK 时,发现 SPDK 缺少一项重要功能——热升级。我们无法 100% 保证 SPDK 进程不会 crash 掉,一旦后端 SPDK 重启或者 crash,前端 QEMU 里 IO 就会卡住,即使 SPDK 重启后也无法恢复。
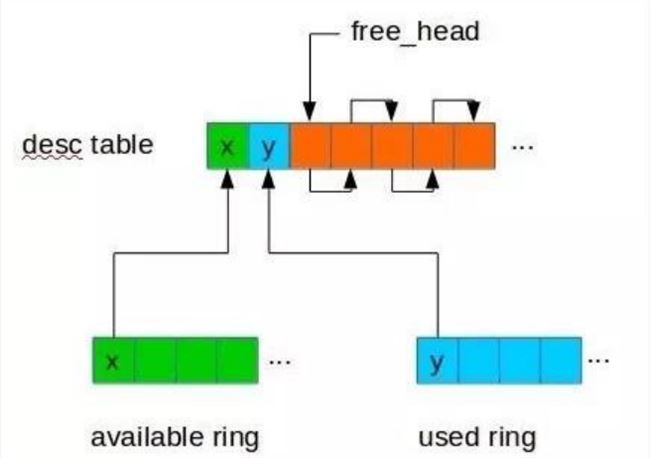
图:virtio vring 机制示意
通过深入研究 virtio vring 的机制,我们发现在 SPDK 正常退出时,会保证所有的 IO 都已经处理完成并返回了才退出,也就是所在的 virtio vring 中是干净的。而在意外 crash 时是不能做这个保证的,意外 crash 时 virtio vring 中还有部分 IO 是没有被处理的,所以在 SPDK 恢复后需要扫描 virtio vring 将未处理的请求下发下去。
针对该问题,我们在 QEMU 中针对每个 virtio vring 申请一块共享内存,在初始化时发送给 SPDK,SPDK 在处理 IO 时会在该内存中记录每个 virtio vring 请求的状态,并在意外 crash 恢复后能利用该信息找出需要重新下发的请求,实现 SPDK 的热迁移。具体可查看https://mp.weixin.qq.com/s/UBRJhN58VQwDCHYZyDP02w 了解。
2、RDMA 网络加速
(1)TCP 瓶颈
在解决了 IO 路径优化问题后,我们继续寻找提高云盘 IO 读写性能的关键点。在协议层面,我们发现使用 TCP 协议存在以下问题:
■ TCP 收发数据存在网卡中断开销,以及内核态到用户态的拷贝开销;
■ TCP 是基于流式传输的,因此通常网络框架(libevent)会使用一个缓冲区暂存数据,等到数据达到可处理的长度才从缓冲区移除,同样地,发包过程为了简化 TCP 缓冲区满引起的异常,网络框架也会有一个发送缓冲区,那么这里就会产生二次拷贝。

图:TCP 协议原理示意
针对这个问题,我们用 RDMA 协议来代替 TCP 协议,来达到提升 IOPS 和时延的能力。
(2)RDMA 代替 TCP
RDMA(Remote Direct Memory Access) 技术全称远程直接数据存取,是为了解决网络传输中服务器端数据处理的延迟而产生的。
使用 RDMA 代替 TCP 的优点如下:
■ RDMA 数据面是 bypass kernel 的,数据在传输过程中由网卡做 DMA,不存在数据拷贝问题。
■ RDMA 收发包过程是没有上下文切换的,发送时将数据 post_send 投递到 SQ 上,然后通知网卡进行发送,发送完成在 CQ 产生一个 CQE;接受过程有一些差异,RDMA 需要提前 post_recv 一些 buffer,网卡收包时直接写入 buffer,并在 CQ 中产生一个 CQE。
■ RDMA 为消息式传输,即假设发送方发送一个长度为 4K 的包,接收方假如收到了,那么这个包的长度就是 4K,不存在只收到一部分的情况。RDMA 提供的这种能力可以简化收包流程,不需要像 TCP 一样去判断数据是否收全了,也就不存在 TCP 所需的缓冲区了。
■ RDMA 的协议栈由网卡实现,数据面 Offload 到网卡上,解放了 CPU,同时带来了更好的时延和吞吐。
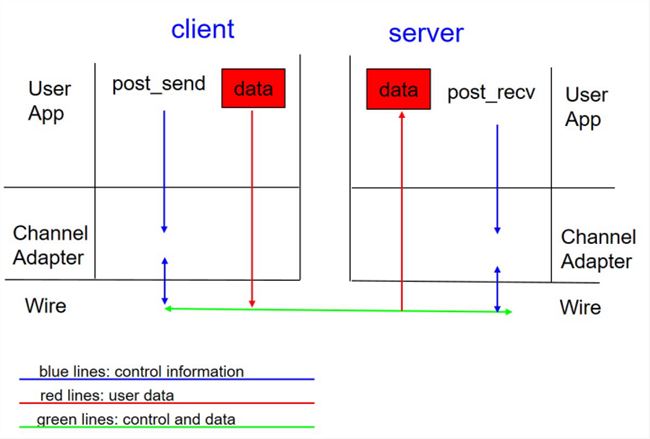
图:RDMA 协议原理示意
3、后端存储节点 IO Path 加速
除了在 IO 路径接入与传输协议方面做了改进之外,UCloud 还针对云硬盘后端存储节点进行了优化。
对于原有的 Libaio with Kernel Driver,我们采用了 SPDK NVMe Driver 进行了替代,下图为 Fio 对比测试两者的单核性能情况,可以看到应用 SPDK NVMe Driver 后性能有了较大的提升。
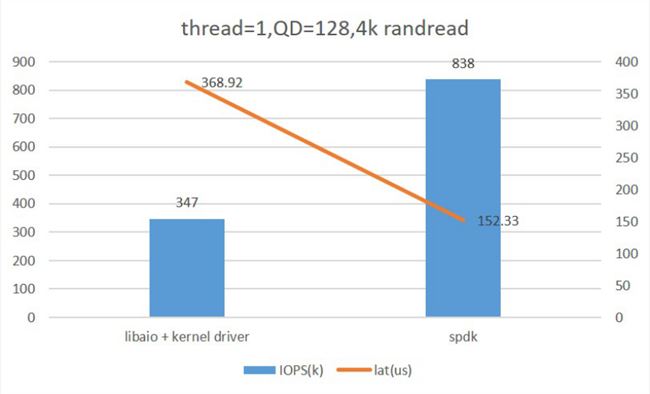
图:Libaio with Kernel Drive & SPDK NVMe Driver 单核性能比较
此外,SPDK NVMe Driver 使用轮询模式,可以配合 RDMA 发挥出后端存储的最佳性能。
综上,我们实现了云盘的全面优化:使用 SPDK VHost 代替 QEMU,实现虚机到存储客户端的数据零拷贝;使用高性能 RDMA 作为后端存储的通信协议,实现收发包卸载到硬件,使得 RSSD 云盘的延迟降低到 0. 1 毫秒,体验几乎和本地盘一致;存储引擎由 SPDK 代替 libaio,高并发下依然可以保持较低的时延。再配合全 25G 的底层物理网络,使 RDMA-SSD 云盘的随机读写性能达到最佳,实现 120 万 IOPS。
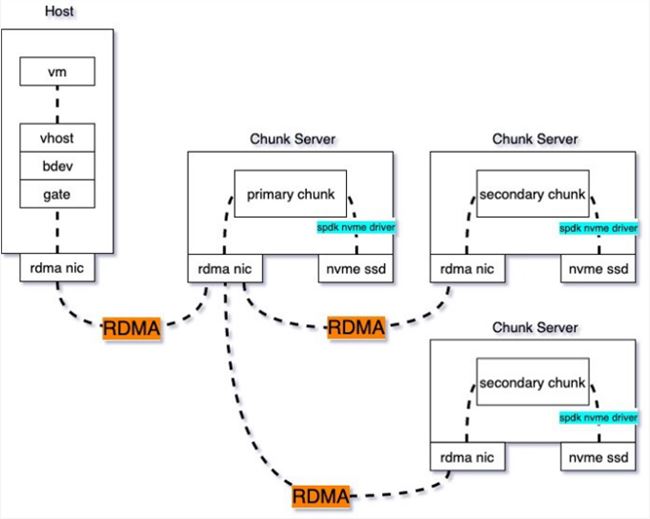
图:RDMA-SSD 云硬盘原理图
三、内核调优:产品综合性能提升 10%
提起云主机,更多的会想到计算、存储、网络,甚少有人关注内核。然而,内核构建是一个云主机的核心工作,它负责管理系统的进程、内存、设备驱动程序、文件和网络系统等,对云主机性能和稳定性至关重要。
未优化之前,我们对云主机中特定业务场景进行了基准性能测试。在测试过程中,利用 perf、systemtap、eBPF 等多种动态跟踪技术,在 Host 内核、KVM 和 Guest 内核等不同观测层级上,对影响性能的因素进行了指令级别的分析。
在此基础上,我们针对性的进行了内核增强和优化工作。
■ CPU 增强 & 漏洞修复
我们在 QEMU 和 KVM 中添加了 Intel 新一代 Cascade Lake 虚拟 CPU 的支持,相比上一代 Skylake,增加了 clflushopt、pku、axv512vnni 等指令集,在特定场景下性能表现更加出色。此外,针对 CPU 漏洞方面,我们利用硬件解决了 Meltdown,MDS,L1TF 等漏洞,同时针对 Spectre_v2 补丁添加了代价更小的 Enhanced IBRS 增强修复机制,在虚拟化层面对漏洞进行了修复。

最后,我们将硬件修复能力赋予”快杰”,使得云主机可以避免 Guest 内核在软件层面修复安全漏洞,消除这方面引起的性能开销和业务指标下降。
■ CPU 对内存读写能力的优化
针对 CPU 对内存读写能力的优化,我们主要从两方面来实现。
首先我们基于硬件内存虚拟化(Intel EPT),添加了定制化大页内存的支持,从而避免了之前内存虚拟化中存在的管理器 / 分配器开销、换页延迟等,极大减少了页表大小和 TLB miss,同时保证云主机内存与其他云主机、系统软件间相互隔离,避免影响。
其次,我们增强了 NUMA 亲和性的使用。众所周知,跨节点访问内存的延迟远远大于本地访问所产生的,针对该问题,我们通过合理的资源隔离和分配,使云主机的 VCPU 和内存绑定在同一个节点。此外,对于大型云主机可能存在单个节点资源不够的情况,我们将云主机分配在两个节点,把节点的拓扑结构暴露给 Guest 内核,这样云主机可以更方便的利用 NUMA 特性对关键业务进行调度管理。
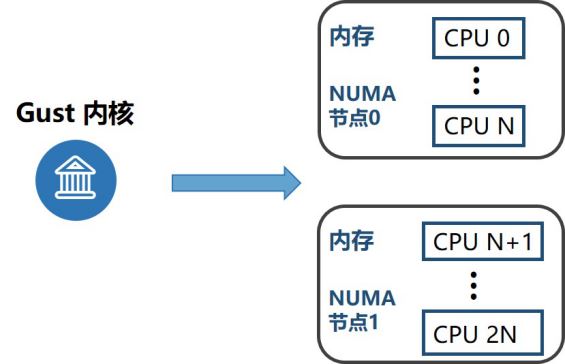
图:NUMA 亲和性的使用
■ Host 内核 &KVM 优化
结合性能分析数据,我们对 Host 内核和 KVM 也进行了大量的优化。
在 VCPU 调度方面,我们发现 CFS 调度器会在临界区内使用时间复杂度为 O(n) 的算法,导致调度器开销过高、Guest 计算时间减少及调度延迟增大,我们在 CFS 中修复了这一问题。
此外,在 Host/Guest 上下文切换过程中,我们发现某些寄存器的上下文维护代码会引入一定开销,因此在保证寄存器上下文切换正确性的同时,我们也去掉了这些维护代码引起的开销。
在云主机运行过程中,会产生大量的核间中断(IPI),每次 IPI 都会引起 VMExit 事件。我们在虚拟化层引入了两个新的特性:KVM-PV-IPI 和 KVM-PV-TLB-Flush。通过 KVM 提供的 Send-IPI Hypercall,云主机内核可以应用 PV-IPI 操作消除大量 VMExit,从而实现减少 IPI 开销的目的。在云主机更新 TLB 的时候,作为发起者 VCPU 会等待其它 VCPU 完成 TLB Shootdown,云主机内核通过 PV-TLB-Flush 极大减少等待和唤醒其它 VCPU 的开销。
以上是一些比较重要的优化工作,其它内核、KVM、QEMU 功能增强和稳定性提升等内容不再赘述。总体评估下来,通过内核调优,可帮助”快杰”实现 10% 以上的综合能力提升。
四、三大应用场景分析
基于强大的性能,“快杰”能够轻松满足高并发网络集群、高性能数据库、海量数据应用的使用场景。我们分别选取了 Nginx 集群、TiDB、ClickHouse 数据库三个应用场景,下面来看一下”快杰”的表现:
■ 场景 1::搭建 Nginx 集群,突破网络限制
爱普新媒是一家从事广告 DSP(Demand-Side Platform,需求方平台)业务的公司,由于业务需求,爱普新媒对于网络集群的高并发要求非常高。最终,爱普新媒选择使用“快杰”搭建 Nginx 集群,作为 API 网关对其终端客户提供服务。
Nginx 是一款轻量级 HTTP 反向代理 Web 服务器,根据 Nginx 官网的数据,Nginx 支持了世界上大约 25% 最繁忙的网站,包括 Dropbox,Netflix,Wordpress.com 等。其特点是并发能力强,而“快杰”进一步提升了其并发能力。
“快杰”突破了云主机之前的网络限制,如下图,“快杰”的应用使得爱普新媒原有集群内主机可以大幅度减少,并且在相同服务能力下,成本减半。
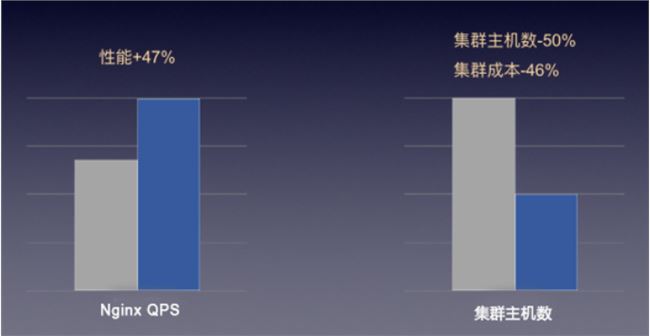
图:“快杰”在高并发网络集群场景中的表现
■ 场景 2: 搭建 TiDB,突破 IO 性能瓶颈
PingCAP 的 TiDB 是一款流行的开源分布式关系型数据库,为大数据时代的高并发实时写入、实时查询、实时统计分析等需求而设计,对 IO 性能的要求无疑非常高。通常,TiDB 要求底层使用 NVMe SSD 本地磁盘支撑其性能,但快杰云主机通过 RSSD 云盘即可满足 TiDB 的高要求,其性能得到 PingCAP 工程师的实测认可。
目前,已有不少 UCloud 客户使用快杰云主机搭建 TiDB,突破了之前的数据库性能瓶颈。
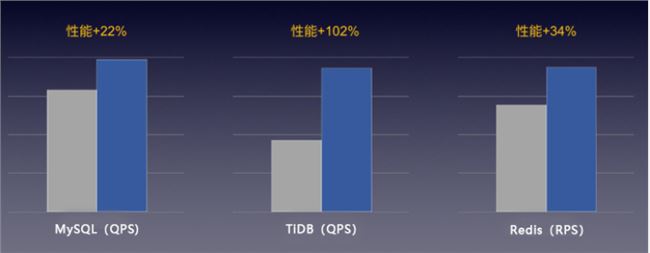
图:“快杰”在高性能数据库场景中的表现
除了 TiDB,“快杰”实测能有效提升各类数据库的性能表现 20% 以上。
■ 场景 3: 搭建 ClickHouse, 2 倍提升数据吞吐量
TT 语音是一款专门为手游玩家服务的语音开黑工具,由于业务要求需将 APP 埋点数据收集到大数据集群中分析。TT 语音采用“快杰”搭建 ClickHouse 数据库作为整个大数据集群的核心,对比之前,每日增量达到 8 亿条记录。
除了 ClickHouse 场景,“快杰”还可以对大数据生态进行全方位的优化,如下图,数据吞吐提升高达 2 倍,助力企业大数据业务发展。

图:“快杰”在大数据应用场景中的表现
结语
基于“软硬件协同设计”的理念,“快杰”在网络增强 2.0、RSSD 云盘优化、内核调优等方面做到了技术的大幅进阶,为用户带来了突破性的云主机性能提升。在“快杰”的技术进阶路上,技术的更迭与升级可以用语言描述出来,但是技术实现的背后却代表了 UCloud 为用户创造核心价值的坚持与追求。
(免责声明:本网站(https://c.shenzhoubb.com)
内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。)