
八年之痒!除了 NLP 和 CV,人工智能就不能干点别的啥了?
大数据文摘出品
来源:medium
作者:Sergii Shelpuk
编译:王转转、junefish、武帅、钱天培
从 2012 年 AlexNet 惊艳亮相开始算起,AI 已经经历了将近 8 年的蓬勃发展期。
这一迅猛发展尤其反映在了 AI 顶会的参会数据上。2013 年,ICML 的参会人数仅有数百名,但到了 2018 年,这一数量上升到了 5000 多。2019 年 12 月,机器学习领域的最大型的会议 NeurIPS 更是聚集了 13000 名 AI 研究人员和工程师。
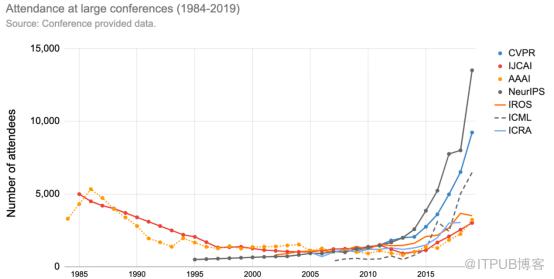
大型会议参会人数变动图
AI 研究人员的迅速涌入也直接导致了论文数量的爆炸增加。如今,arXiv 已有六万多篇 AI 论文。
2013 年,一位 AI 专家可能会熟悉其子领域中的所有出版物。在 2019 年,这是不可能的。如今,行业中的绝大多数 AI 工程师都依赖“最佳论文”和其他简要名单来了解最新成果。
从最开始星辰大海般的探索,到如今研究领域的细分再细分,AI 研究似乎也进入了“小修小补”阶段。
那么,AI 研究中我们能够解决的重大问题是否已经完全被解决了呢? 下一次的 AI 大突破是否就要等待新的里程碑式的研究呢?
AI 基因研究公司 Deeptrait 的创始人 Sergii Shelpuk 认为,我们在这一轮 AI 发展期中依旧大有可为。
除去自然语言处理和计算机视觉两大领域,我们还有太多领域可以开拓。
下面,我们对 Sergii Shelpuk 的观点进行了编译整理。
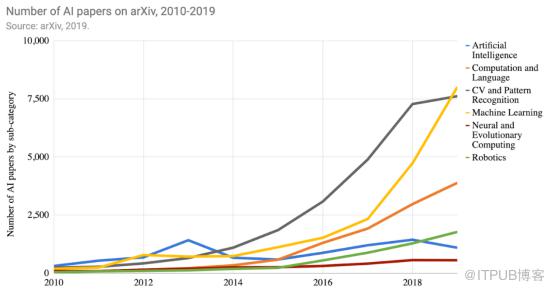
arXiv 上 AI 子类论文数量变动图
首先,让我们来梳理一下如今 AI 从业者面对一个新问题时的常见心路历程。
以计算机视觉为例,只需看一看图像识别的最新技术,然后选择适合要求的体系结构即可。在比如自然语言处理,如果需要进行情感分析等任务,同样只需浏览有关此问题的出版物,然后选择适用于您的数据,硬件和所需性能的解决方案。
即使现有出版物不存在针对特定问题的解决方案,它也涉及“关于子问题的子问题”。例如,传统的数据增强技术无法给你的数据集带来理想的结果,或者,神经网络在收集到的数据集中表现不佳,亦或是最佳的词语嵌入技术在特定任务情境下表现不佳,等等。
这些年来,人们不断遇到这些关于子问题的子问题,似乎关于 AI 的所有重大问题都已得到解决,越来越多的针对不断缩小的研究领域的论文的发表更加强化了人们的这种印象。
当我们开始使用 DeepTrait 开发用于基因组分析的 AI 系统时,我们查阅了现有文献。我们以为,深度学习的研究者已经详细探讨过所有相关的问题,例如异构数据分析。如今,基因组分析已成为人类研究中最有前途和最重要的领域之一,并且该领域中总共已有 6 万多篇 AI 论文发表。研究者们肯定已经完成了相对广泛而深入的工作,不是吗?
但事实证明并不是。在 2019 年 12 月 12 日访问 arXiv 并搜索“深度学习”,共有 22,140 篇论文。然而将搜索内容更改为“深度学习基因组”后,发现只有 76 篇相关的论文,其中许多论文并未解决基因组数据的问题,只是提到基因组是未来潜在的相关应用方向。
在其他论文来源(包括 bioRxiv)中搜索有关基因组学的深度学习论文,也就仅有 200 多篇。其中绝大多数运用的还是过时的神经网络架构和训练技术,另外很大一部分错误地使用了这些工具,例如,将卷积神经网络应用于异构数据(例如 SNP),这导致了模型表现不佳。我们发现这样的论文并不在少数。
那些正确使用 AI 工具的人主要将其应用在分析基因组的较小子序列,例如启动子或蛋白质结合位点。他们的输入数据最长为一到两万个核苷酸。相比之下,拟南芥基因中的核苷酸数量接近 1.35 亿,而这仅仅是我们在第一次测试中所使用的基因之一。因此,我们没有现成的范例或已有的神经网络架构可供参考,也没有针对这种大小序列的训练技术,完全没有!我们必须从头开始。

大家都在研究什么?
我感到奇怪,因为研究基因组数据具有巨大的潜力。高通量测序可产生大量数据,而 AI 似乎是理所当然的研究工具。然而,按论文的比例衡量,基因组学只占 AI 研究关注的 1%。
那么剩下的 99%在哪里?基因组数据的 AI 应用显然是一个机遇,如果这样一个宝贵的研究课题都被忽视了,那么也许还有更多研究课题有待探索。
我回到 arXiv 寻找其他潜在的 AI 应用方向。例如,现代天文学会生成大量数据:影像数据、射频、带注释的天体(包括天空的最小部分)等。还有可能改变我们对宇宙认知的重大问题,例如“什么是暗物质?”,例如恩里科·费米(Enrico Fermi)所提出的著名问题的“他们都在哪呢?”
利用 AI 的力量通过分析宇宙中探测到的天文数据来解决这些重要的谜题,应该是一个显而易见的方向,不是吗?
然而现在在 arXiv 搜索“深度学习暗物质”,却只有20 个结果。
接下来是什么?材料科学?现代强化学习模型可以击败围棋和星际争霸 2 中最好的人类玩家。这些模型的表现如此出色,以至于 AlphaGo 的胜利被刊登在《自然》杂志上,最近,世界上排名最高的围棋选手李世石选择退役,留下一句话,“AI 难以被击败”。(注:李世石的原话是“即使我成为棋手中的第一,我也无法站到顶点了,因为还有一个个体是我无法打败的。”听起来好悲壮 o(╥﹏╥)o )
这个消息令人鼓舞,将相同的方法应用于材料科学怎么样?人类已经对物理和化学了解很多。我们可以构建一个模拟器,在其中可以通过强化学习来学习如何自行创建新材料(例如石墨烯)。这些新材料可以创造出新的飞机和舰船,空间升降机,水下站,甚至帮助人类移民到外太空。这应该是一个有趣的研究方向。
然而,arXiv 上只有16 篇有关“深度学习晶体结构”的论文。
这世界真小
事实证明,几乎所有现代 AI 研究和工业应用都聚焦于两个子领域中的十几个技术问题:计算机视觉和自然语言处理。
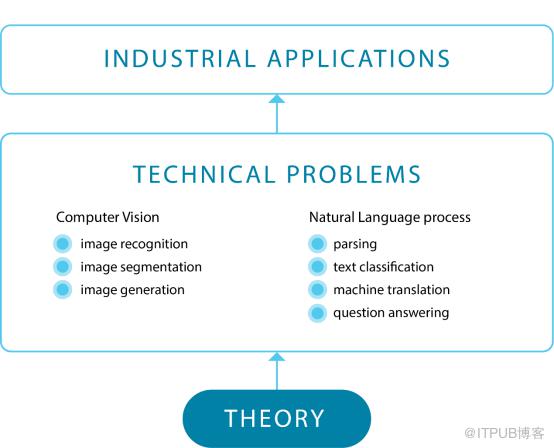
AI 创新的反向金字塔
我们可以使用倒金字塔为 AI 世界建模。每个较低的层级都启发较高的级别模式,对其进行具象化并在某种意义上对其进行定义。
最底层是非常深入的基础科学和技术。它涉及对神经网络,算法优化,统计属性以及这些工具的概率性质的理论理解。
中间存在一个技术层面的问题。这就是我前面提到的十几个技术子问题。对于计算机视觉而言,它们是用于 NLP 的图像识别,图像分割和图像生成,包括解析,文本分类,机器翻译和问题解答等方面,其中通用语言理解评估(GLUE, General Language Understanding Evaluation)基准很好地代表了后者。
大多数研究人员和行业专家都处于这一级别。当然不是所有的人都专注于涉及 GLUE 或视觉任务的研究,你可能就是一个例外而不同意我的说法。但是,作为局内人,你可以清楚地明白我们中有多少人处于这个级别之中,又有多少人从事与这份任务清单本身、变形或组合之外的工作。
中间层的界限取决于理论科学底层的发展状况。在底层出现的任何新想法,例如梯度下降,存储单元或卷积滤波器,都可以在技术问题级别实现一系列新动作。
正如理论科学的进步可以实现整个技术领域的扩展一样,解决单个技术问题也可以实现金字塔顶端的一系列工业应用成为可能。
该模型说明了行业的一个基本限制:虽然将产品从技术问题的层次转换到工业应用相对简单,但是反过来则难以实现。将应用程序流程视作一系列单向箭头,如果我们在技术水平上只有一群特定的计算机视觉和自然语言处理工具,那么许多工业应用将无法实现。如果事实是这样,绝大多数人都会这样做。一位需要设计工业应用程序的 AI 专家最初希望在技术层的某个地方找到答案,但实际上可能会走向更广泛且令人兴奋的技术问题。
走进 AI
技术问题和工业化实践的当前状态使得从应用程序到现有技术工具的反向路径几乎难以实现。现有的 AI 工具箱是为计算机视觉和自然语言处理(NLP)中特定的应用量身定制的,而这些工具越先进,其关注范围就越窄。
以数据的大小为例,在植物基因组学中,我们从拟南芥的 1.35 亿个字母基因组开始。如果将其按比例成卷打印,一个拟南芥基因组的每个数据点将占用 150 卷,这还仅仅只是开始。番茄基因组将生成 9.5 亿个字母文本或 1,055 卷印刷量,大麦将生成 53 亿个字母或 5,888 卷,小麦将生成 170 亿个字母或 18,888 卷。当前的 NLP 无法处理这么大数据量的任何东西,我们目前所有的用于 NLP 的现代深度学习工具,例如类似变压器的网络,只能处理长达数千个元素的序列。
另一个例子是数据的性质。基因组由四个离散的核苷酸组成,这些核苷酸由四个字母分别表示:A,C,T 和 G。一个核苷酸的 T 字母数量不容许出现多一个或者少一个的任何偏差,此外,将单个 T 更改为其他字母,则可能导致完全不同的表型,致命疾病或致死性疾病。
上述潜在问题都限制了为连续数据开发的计算机视觉技术的使用。将这些数据规模加总,以方形四通道图像表示的人类基因组将具有 54,772 x 54,772 像素的分辨率,这远远超过了现代计算机视觉神经网络可以处理的分辨率水平。
基因组数据的性质和大小对我们目前所有最先进的深度学习技术提出了挑战,在计算机视觉或 NLP 领域中迄今还没有可借鉴的神经网络体系或训练实践能够解决上述问题。
天文学,化学,材料科学等数据丰富的学科,都存在着类似的问题:它们无法使用局限于狭窄的计算机视觉和 NLP 解决方案的现有 AI 工具集。目前有几种流行的解决方法,例如将十六进制数据转换为图像,调整其大小之后再使用计算机视觉工具等,但它们并没有太大帮助。
在这一点上,那些坚持不懈地寻求解决方案的人别无选择,只能进入人工智能的最深层次,即理论层次。 AI 生态系统的这一根源促使了很多发现,包括关于深度神经网络如何工作,不同体系结构如何影响其行为,不同激活功能如何与特定数据分布相互关联等。换句话说,你可以使用这些工具创建自己的工具箱,并应用于你关心的工业程序。
这是一场艰难的旅程,它需要时间,深厚的专业知识,奉献精神和些许运气,但最终,你将在 AI 生态系统中开发出全新的技术问题层。尽管是为特定的工业应用而构建的,但该新工具集可以很多解决其他问题,例如解决图像识别的技术可以为各种产品和产品原型提供新的思路,从放射学分析到自动驾驶系统例如 Tesla Autopilot 等都将受益于此。
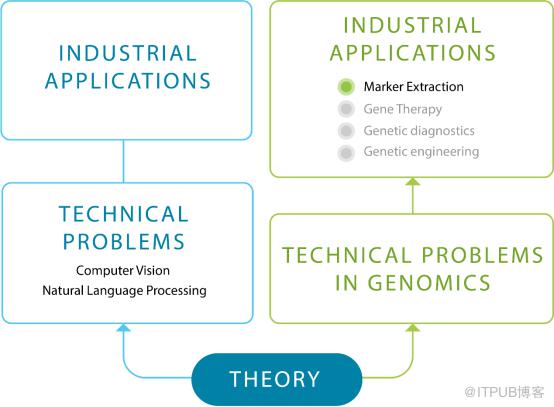
新技术问题层使一系列新的工业应用成为可能
蓝海
解决计算机视觉和 NLP 的技术问题是一条非常可靠,可预测和安全的途径。在这些领域有很多研究小组,初创公司和知名公司。专门研究计算机视觉或 NLP 还可以确保你接触到前沿的工具,包括数据集,GPU 技术,框架,以及大量的开源存储库等,这些储存库囊括了示例,库,基准测试和其他有用的资源。好的工具可以减轻我们的工作负担并提高生产力,这也许可以解释为什么 AI 人才在这两个特定领域中聚集。
另一方面,创造自己的用于天文学,遗传学,化学,材料科学,地球科学或经济学的 AI 工具箱是一项充满挑战,甚至偶尔令人沮丧的孤独旅程,你只能依靠自己和你的团队。但是,它可以使整个领域收益,足以建立另一个十亿美元级别的公司或一个研究机构。
目前,人类面临着许多至关重要但尚未解决的问题。对于其中的许多问题来说,那些勇敢的先驱们已经收集了多到无法分析的大量数据。他们的目的很简单,收集数据并继续前进。这些数据就在那里,等着人们去发现它的价值,但是有时这需要花费数年的时间。这些问题中还有许多仍未得到解答,因为它们被证明是无法明确解决的。但是,人工智能技术也因此而闻名,因为它能够学习如何破解无法解决的问题。
远离拥挤的人潮,静坐冥思,你会发现整个世界都被 AI 社区所忽视了。这个世界等待了数十年,翘首以盼那些 AI 先驱的到来。没有地图,没有线索,它们只把自身的价值送给那些勇于探索并一往无前的人。
(免责声明:本网站(https://c.shenzhoubb.com)
内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。)