
智能运维大数据处理时发生数据倾斜的解决方案
为何会发生数据倾斜?
19 世纪末意大利经济学家帕累托发现在任何一组东西中,最重要的只占其中一小部分,约 20%,其余 80% 尽管是多数,却是次要的,因此又称二八定律,又叫帕累托法则。

因此,正常的数据分布理论上来说都是会发生倾斜的,例如,在进行运维大数据分析时,80% 的故障异常都是由 20% 的常见运维问题导致的,因此,会导致少数的问题有非常多的记录。
数据倾斜产生原因:
MapReduce 模型中,数据倾斜问题是很常见的,因为同一个 Key 的 Values,在进行 groupByKey、countByKey、reduceByKey、join 等操作时一定是分配到某一个节点上的一个 Task 中进行处理的,如果某个 Key 对应的数据量特别大的话,就会造成某个节点的堵塞甚至宕机的情况。在并行计算的作业中,整个作业的进度是由运行时间最长的那个 Task 决定的,在出现数据倾斜时,整个作业的运行将会非常缓慢,甚至会发生 OOM 异常。
解决方案
一、使用 Hive ETL(提取、转换和加载) 预处理数据
Spark 作业数据通常来源于 Hive 中,如果发生倾斜的数据来源于 Hive 表,可以通过 Hive 来进行数据预处理。直接通过 Hive ETL,对数据预先进行聚合或 join 等操作,直接生成结果数据表,这样在 Spark 作业中针对的数据源就是预处理过后的 Hive 表,就不需要再去执行 Shuffle 类的算子了,从根源上解决了数据倾斜。
但是,因为数据本身就存在着分布不均的问题,所以在 Hive ETL 进行数据处理时,还是会发生数据倾斜,作业速度变慢的问题,这种解决方案只是避免的 Spark 作业时的数据倾斜问题。
二、提高 Reduce 任务的并行度
将 Reduce Task 的数量变多,就可以让每个 Reduce Task 分配到更少的数据量,这样可以缓解数据倾斜的问题。
在调用 groupByKey、countByKey、reduceByKey 时,传入 Reduce 端的并行度参数,这样在进行 Shuffle 操作时,会创建指定的 Reduce Task,可以让每个 Reduce Task 分配到更少量的数据,避免了 Spark 作业时 OOM 的情况。
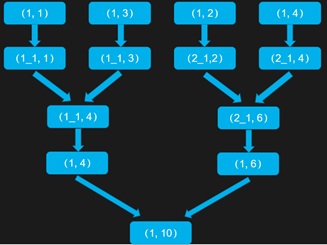
三、使用随机 Key 进行分步聚合
在 groupByKey、reduceByKey 操作时,第一次聚合的时候,对 Key 加一个随机前缀,例如 10 以内的随机数,将 Key 进行打散操作,将 Key 分为多组后,先进行局部聚合,在第二次聚合的时候,去除掉每个 Key 的前缀,再所有 Key 进行全局的聚合。
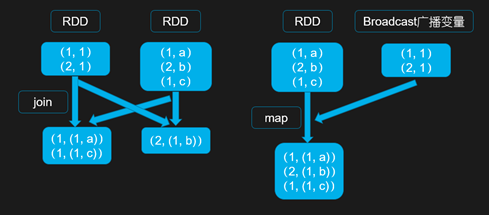
四、使用广播数据避免 Reduce 操作
当两个 RDD 要进行 join 操作时,其中一个 RDD 是比较小的,将较小的那个 RDD 进行 Broadcast 操作后,不使用 join 进行两个 RDD 的连接,因为普通的 join 操作是会触发 Shuffle 过程的,一旦触发 Shuffle 会将相同 Key 的数据都拉取到同一个 Task 中进行处理,而使用 map join 从广播变量中获取较小的 RDD 中的数据进行连接操作,不会触发 Shuffle,避免了数据倾斜的发生。
但是,如果两个 RDD 都比较大,将其中一个 RDD 的数据进行 Broadcast 后,数据将会在每个 Executor 的 Block Manger 中都驻留一份,很有可能导致内存溢出,程序崩溃。
五、将发生数据倾斜的 key 单独进行 join
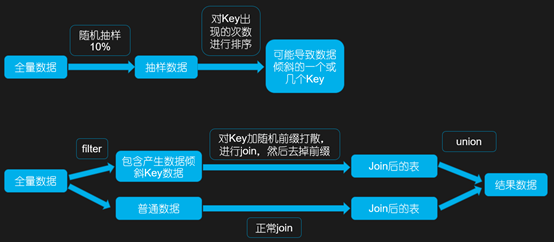
首先通过 Spark 中的 sample 算子对数据进行随机抽样,然后对抽样出的数据中 Key 出现的次数进行排序,这样就可以找到导致数据倾斜的一个或多个 Key,然后对数据进行 Filter 操作,可以将产生数据倾斜的 Key 和普通 Key 的数据分离,生成两个 RDD。
对于可能产生数据倾斜的 RDD,给每条数据都打上随机数进行打散操作后,再去进行 join,然后去除前缀后再跟普通 RDD 进行 join 后的结果,进行 union 操作。
这种方案只需要针对数据中有少量导致数据倾斜的 Key,如果导致数据倾斜的 Key 特别多,则不适用。
六、使用随机数和扩容表进行 join
若在 join 操作时,RDD 中有大量的 Key 导致了数据倾斜,可以考虑选择一个 RDD 进行扩容,将每条数据映射为多条数据,每条数据都带有 0~n 的前缀。另一个 RDD 的每条数据都打上一个 n 以内的随机值前缀。然后,将两个 RDD 进行 join 操作后,再去掉前缀。
此方案与方案五的区别在于,当有大量导致数据倾斜 Key 的情况时,没法将部分 Key 拆分出来单独处理,因此只能对整个 RDD 进行数据扩容,对资源要求很高。

总结
方案 1 使用 Hive 进行数据预处理,适用于对 Spark 作业执行性能要求较高的场景,将数据倾斜在 Hive ETL 中解决,只有在 Hive ETL 周期性处理数据时作业速度较慢,其余的每次 Spark 作业速度都将很快;
方案 2 提高 Reduce 任务的并行度,指标不治本,因为,没有从根本上改变数据倾斜的本质和问题,只是缓解了执行 Reduce Task 时的压力;
方案 3 使用随机 Key 进行分步聚合,适用于 groupByKey、reduceByKey 等聚合类的操作;
方案 4、5、6 都是针对于 join 操作时发生的数据倾斜,方案 4 使用广播数据避免 Reduce 操作适用于其中一个 RDD 是比较小的情况,方案 5 将发生数据倾斜的 key 单独进行 join 适用于少量数据倾斜是由少量的 Key 导致的,方案 6 使用随机数和扩容表进行 join 对资源要求很高,适用于大量的 Key 导致了数据倾斜。