
hbase 完全分布式集群部署
1. 简介
HBase 是一个分布式的、面向列的开源数据库,它不同于一般的关系数据库, 是一个适合于非结构化数据存储的数据库。另一个不同的是 HBase 基于列的而不是基于行的模式。HBase 使用和 BigTable 非常相同的数据模型。用户存储数据行在一个表里。一个数据行拥有一个可选择的键和任意数量的列,一个或多个列组成一个 ColumnFamily,一个 Fmaily 下的列位于一个 HFile 中,易于缓存数据。表是疏松的存储的,因此用户可以给行定义各种不同的列。在 HBase 中数据按主键排序,同时表按主键划分为多个 Region。
在分布式的生产环境中,HBase 需要运行在 HDFS 之上,以 HDFS 作为其基础的存储设施。HBase 上层提供了访问的数据的 Java API 层,供应用访问存储在 HBase 的数据。在 HBase 的集群中主要由 Master 和 Region Server 组成,以及 Zookeeper,具体模块如下图所示:
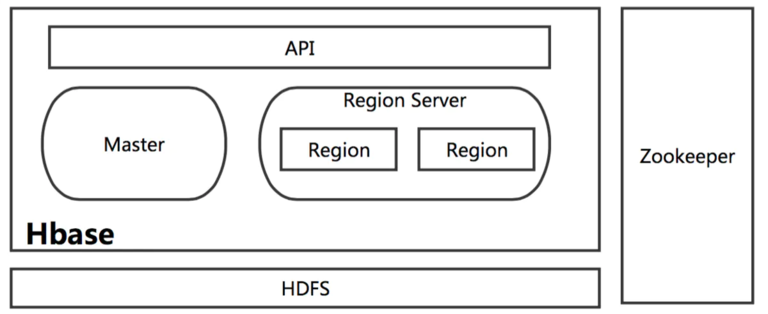
简单介绍一下 HBase 中相关模块的作用:
Master
HBase Master 用于协调多个 Region Server,侦测各个 RegionServer 之间的状态,并平衡 RegionServer 之间的负载。HBaseMaster 还有一个职责就是负责分配 Region 给 RegionServer。HBase 允许多个 Master 节点共存,但是这需要 Zookeeper 的帮助。不过当多个 Master 节点共存时,只有一个 Master 是提供服务的,其他的 Master 节点处于待命的状态。当正在工作的 Master 节点宕机时,其他的 Master 则会接管 HBase 的集群。
Region Server
对于一个 RegionServer 而言,其包括了多个 Region。RegionServer 的作用只是管理表格,以及实现读写操作。Client 直接连接 RegionServer,并通信获取 HBase 中的数据。对于 Region 而言,则是真实存放 HBase 数据的地方,也就说 Region 是 HBase 可用性和分布式的基本单位。如果当一个表格很大,并由多个 CF 组成时,那么表的数据将存放在多个 Region 之间,并且在每个 Region 中会关联多个存储的单元(Store)。
Zookeeper
对于 HBase 而言,Zookeeper 的作用是至关重要的。首先 Zookeeper 是作为 HBase Master 的 HA 解决方案。也就是说,是 Zookeeper 保证了至少有一个 HBase Master 处于运行状态。并且 Zookeeper 负责 Region 和 Region Server 的注册。其实 Zookeeper 发展到目前为止,已经成为了分布式大数据框架中容错性的标准框架。不光是 HBase,几乎所有的分布式大数据相关的开源框架,都依赖于 Zookeeper 实现 HA。
HBase 集群建立在 hadoop 集群基础之上,所以在搭建 HBase 集群之前需要把 Hadoop 集群搭建起来,并且要考虑二者的兼容性。
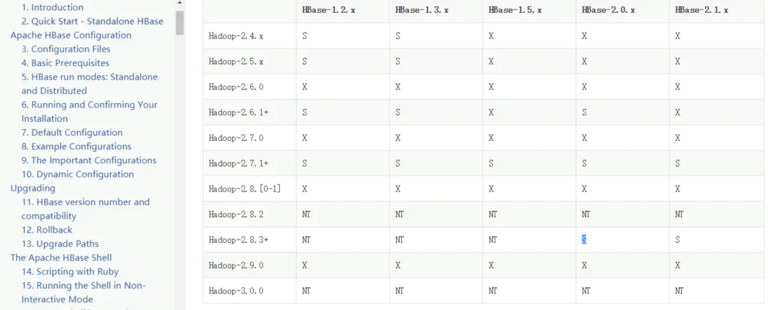
2. 环境准备
(1)各服务器其修改主机名,添加 hosts 文件,关闭防火墙
|
1
2
3
4
5
6
7
8
|
[root@c7001 ~]# cat >> /etc/hosts << EOF
192.168.16.135 c7001
192.168.16.80 c7002
192.168.16.95 c7003
192.168.16.97 c7004
192.168.16.101 c7005
EOF
|
(2)c7001 配置 ssh 免密登陆,用于启动集群
|
1
2
3
4
5
6
7
|
ssh-keygen -t rsa
sh-copy-id -i ~/.ssh/id_rsa.pub c7001
ssh-copy-id -i ~/.ssh/id_rsa.pub c7002
ssh-copy-id -i ~/.ssh/id_rsa.pub c7003
ssh-copy-id -i ~/.ssh/id_rsa.pub c7004
ssh-copy-id -i ~/.ssh/id_rsa.pub c7005
|
(3) 各服务器配置 jdk1.7+
|
1
2
3
4
5
6
7
8
9
|
[root@c7001 ~]# tar zxf jdk-8u171-linux-x64.tar.gz -C /opt/
[root@c7001 opt]# mv jdk1.8.0_171/ jdk1.8
[root@c7001 opt]# vim /etc/profile
export JAVA_HOME=/opt/jdk1.8
export PATH=$PATH:$JAVA_HOME/bin
[root@c7001 ~] source /etc/profile
[root@c7001 opt]# java -version
java version "1.8.0_171
|
3. 安装 hbase
|
1
2
3
4
|
c7003 c7004 c7005
[root@c7003 opt]# tar zxf /usr/src/hbase-1.3.0-bin.tar.gz -C /opt/
|
修改配置文件
|
1
2
3
4
5
6
|
[root@c7003 hbase-1.3.0]# vim conf/hbase-env.sh
#修改 jdk 变量
JAVA_HOME=export JAVA_HOME=/opt/jdk1.8.0_121
#关闭 HBase 自带的 Zookeeper, 使用 Zookeeper 集群:
export HBASE_MANAGES_ZK=false
|
编辑 hbase-site.xml ,添加配置文件:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
hbase.rootdir
hbase.cluster.distributed
true
hbase.zookeeper.quorum
c7003,c7004,c7005
hbase.zookeeper.property.dataDir
/opt/hbase-1.3.0/tmp/zk/data
vi regionservers
#加入如下内容:
c7004
c7005
|
把 Hbase 复制到其他机器
|
1
2
3
|
[root@c7003 opt]$ scp -r hbase-1.3.0 root@c7004:/opt/
[root@c7003 opt]$ scp -r hbase-1.3.0 root@c7005:/opt/
|
启动集群
|
1
2
|
[root@c7003 hbase-1.3.0]$ bin/start-hbase.sh
|
web 访问 ip:16010
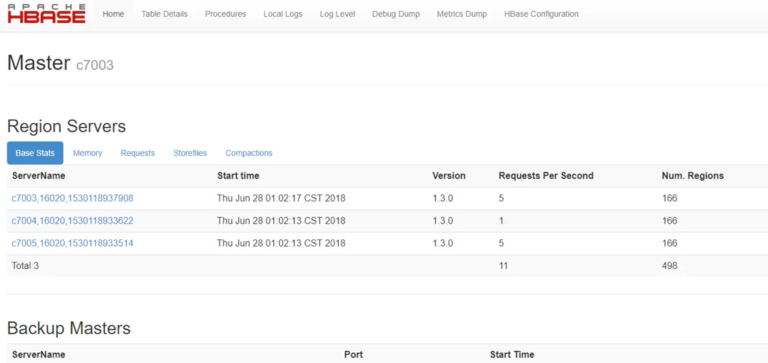
各节点进程(The picture is replicating)
