
终于有人把网络爬虫讲明白了
人们正在以前所未有的速度转向互联网,我们在互联网上所做的很多行为产生了大量的“用户数据”,比如微博、购买记录等。
互联网成了海量信息的载体; 互联网目前是分析市场趋势、监视竞争对手或者获取销售线索的最佳场所,数据采集以及分析能力已成为驱动业务决策的关键技能。
如何有效地提取并利用这些信息成了一个巨大的挑战,而网络爬虫是一种很好的自动采集数据的通用手段。本文将会对爬虫的类型、爬虫的抓取策略以及深入学习爬虫所需的网络基础等相关知识进行介绍。
01 爬虫是什么
网络爬虫 (又被称为网页蜘蛛、网络机器人,在 FOAF 社区中,更经常地称为网页追逐者) 是一种按照一定的规则,自动抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
网络爬虫通过爬取互联网上网站服务器的内容来工作。它是用计算机语言编写的程序或脚本,用于自动从 Internet 上获取信息或数据,扫描并抓取每个所需页面上的某些信息,直到处理完所有能正常打开的页面。
作为搜索引擎的重要组成部分,爬虫首要的功能就是爬取网页数据 (如图 2-1 所示),目前市面流行的采集器软件都是运用网络爬虫的原理或功能。
▲图 2-1 网络爬虫象形图
02 爬虫的意义
现如今大数据时代已经到来,网络爬虫技术成为这个时代不可或缺的一部分,企业需要数据来分析用户行为、自己产品的不足之处以及竞争对手的信息等,而这一切的首要条件就是数据的采集。
网络爬虫的价值其实就是数据的价值,在互联网社会中,数据是无价之宝,一切皆为数据,谁拥有了大量有用的数据,谁就拥有了决策的主动权。网络爬虫的应用领域很多,如搜索引擎、数据采集、广告过滤、大数据分析等。
1) 抓取各大电商网站的商品销量信息及用户评价来进行分析,如图 2-2 所示。
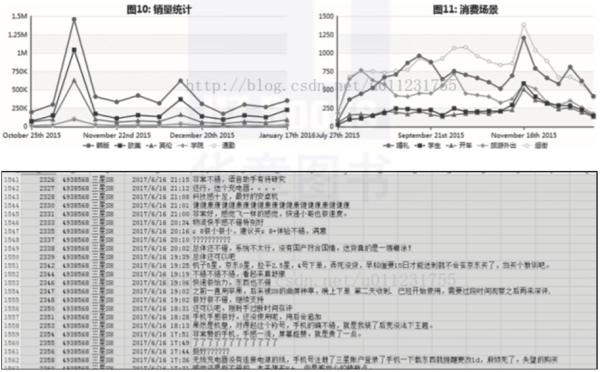
▲图 2-2 电商网站的商品销售信息
2) 分析大众点评、美团网等餐饮类网站的用户消费、评价和发展趋势,如图 2-3 所示。
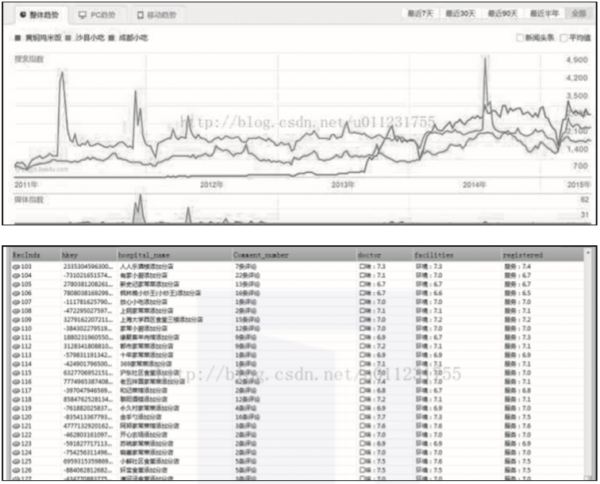
▲图 2-3 餐饮类网站的用户消费信息
3) 分析各个城市中学区房的比例,以及学区房比普通二手房价格高出多少,如图 2-4 所示。
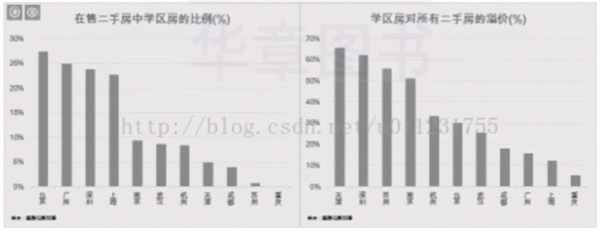
▲图 2-4 学区房的比例与价格对比
以上数据是通过前嗅 ForeSpider 数据采集软件爬下来的,有兴趣的读者可以尝试自己爬一些数据。
03 爬虫的原理
我们通常会将网络爬虫的组成模块分为初链接库、网络抓取模块、网页处理模块、网页分析模块、DNS 模块、待抓取链接队列、网页库等,网络爬虫的各系模块可形成一个循坏体系,从而不断地进行分析和抓取。
爬虫的工作原理可以很简单地解释为先找到目标信息网,然后页面抓取模块,接着页面分析模块,最后数据存储模块。其具体详情如图 2-5 所示。
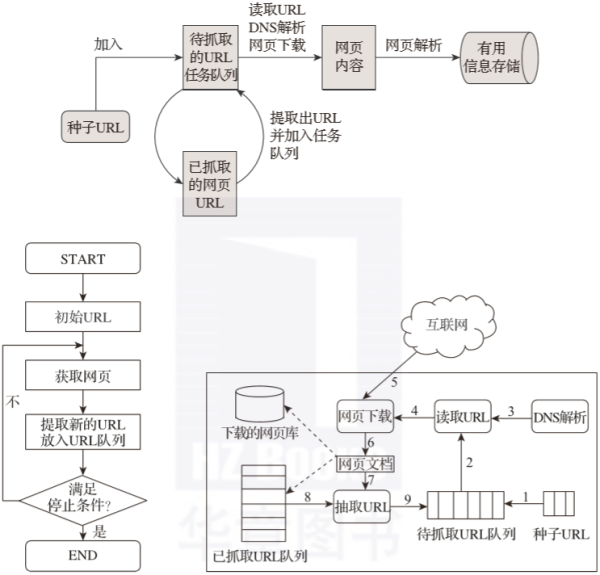
▲图 2-5 爬虫原理图
爬虫工作基本流程:
- 首先在互联网中选出一部分网页,以这些网页的链接地址作为种子 URL;
- 将这些种子 URL 放入待抓取的 URL 队列中,爬虫从待抓取的 URL 队列依次读取;
- 将 URL 通过 DNS 解析;
- 把链接地址转换为网站服务器对应的 IP 地址;
- 网页下载器通过网站服务器对网页进行下载;
- 下载的网页为网页文档形式;
- 对网页文档中的 URL 进行抽取;
- 过滤掉已经抓取的 URL;
- 对未进行抓取的 URL 继续循环抓取,直至待抓取 URL 队列为空。
04 爬虫技术的类型
聚焦网络爬虫是“面向特定主题需求”的一种爬虫程序,而通用网络爬虫则是捜索引擎抓取系统 (Baidu、Google、Yahoo 等) 的重要组成部分,主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。
增量抓取意即针对某个站点的数据进行抓取,当网站的新增数据或者该站点的数据发生变化后,自动地抓取它新增的或者变化后的数据。
Web 页面按存在方式可以分为表层网页 (surface Web) 和深层网页(deep Web,也称 invisible Web pages 或 hidden Web)。
- 表层网页是指传统搜索引擎可以索引的页面,即以超链接可以到达的静态网页为主来构成的 Web 页面。
- 深层网页是那些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户提交一些关键词才能获得的 Web 页面。