
谷歌 SRE 与运维工作的思考
来源 | rrd.me/fR8u9
运维部门要保障产品业务稳定性,开发部门要想随时随地快速上线新功能,而线上的故障往往是由新的变更导致的——不管是新发布了版本,还是修改配置,或者是改变了用户某些行为导致流量负载产生变化,传统意义上这两个部门在本质目标上是相对的。所以运维部门往往会要求开发部门对变更或发布做控制,并且规定要走一些繁琐的流程;而开发部门会想法设法绕过这些繁琐步骤,以支持新功能更快上线。
谷歌的工作方式:面对运维部门与开发部门之间的产品稳定性与迭代创新速度之间的矛盾,允许产品在设定的“错误预算”内发生异常,利用可量化的 SLO 来达到两者之间的平衡。比如一个产品的可用性目标是 99.99%,那么只要这个产品当前的可用性高于 99.99% 情况下,运维团队会尽可能加快产品功能上线;而当这个产品因变更等事故导致可用性低于 99.99%,新的上线和变更请求将不得被处理,直到下个可用性考核周期。
结合我们工作的思考:运维部门从成立之初就建立产品可用率制度,与产品一起设立可用率目标,可以说在量化运维质量目标与平衡产品迭代速度方面做得还可以。可以提升的地方在于推进产品开发部门对可用率目标的重视程度,以及事故改进的协作程度,有些产品往往一味追求产品迭代创新速度而牺牲较多产品稳定性,并且事故改进投入精力不足。
2. 运维工作工程化
谷歌 SRE 通过软件工程的方式去提高运维效率和解决问题,鄙视手工方式操作,一是传统运维方式对于快速发展的业务及达到百万服务器规模的数据中心,通过堆人的方式已经远远满足不了了,二是谷歌 SRE 对自身工作的定位与追求,以开发软件工程模式从繁琐的重复性、机械性工作中抽脱出来,深入到系统架构、业务中,提高自身运维效率和系统整体的可用性可靠性。
对比思考:
最近两三年,随着网易云音乐、考拉海购等产品业务的迅猛发展,杭研体系整体的服务器规模数也快速增长,运维部门统计到的支持工单量也已从 2016 年上半年日均 210 个上涨到 2016 下半年日均 315 个、2017 上半年日均 319 个,在整体人数保持稳定情况下需要在运维效率方面做可持续性提升。
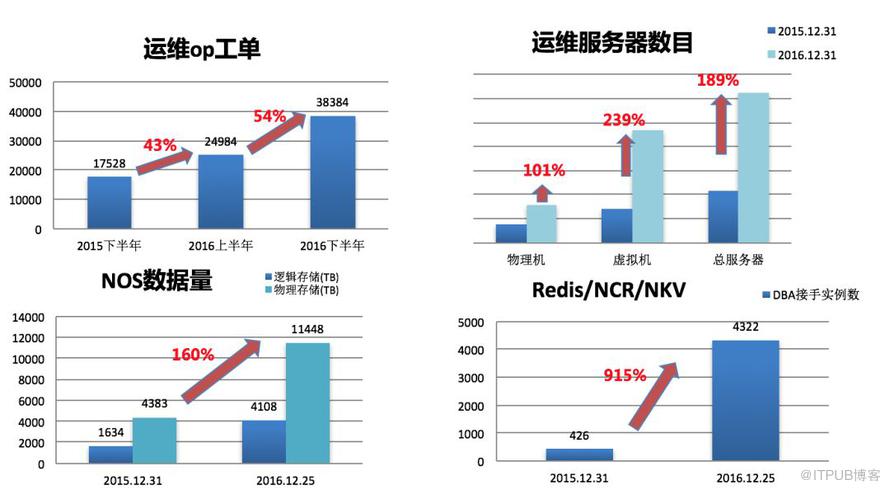
为此,整个运维部门在 2017 年初确定落实 DevOps 战略,对运维工作效率提升做了明确的量化目标,包括工单处理时长、自动化完成率、开放与自助化率等。同时在运维平台建设方面,在流程串联和数据互通、效率提升方面会做更多优化改进;另外运维部 PE、SA、DBA 等各组为优化自身日常工作,各自衍生开发了自己的管理平台——凤凰、FL、OWL,并且这些系统的数据与流程都会连通。到 2017 年底,我们的目标是有 50% 的工单可以由开发部门自助完成,基本上大部分操作可以由 Stone 移动化处理,整体工作效率同比提升 50% 以上。
3. 琐事与 on-call 轮值
谷歌 SRE 强调将日常琐事工作量控制到 50% 上限,能有一半时间投入到工程开发中去。琐事,包括 on-call 值班、中断性事务(工单、邮件和 IM)、发布、数据更新恢复相关等。日常琐事过多,工作经常被中断,是运维工作效率无法提升的一个难题,谷歌 SRE 破解这个难题主要有 2 个方式,一是通过 on-call 轮值的值班制度,让一部分人能够有整段的时间去做工程;二是从整体上评估运维琐事工作量,增派人力或将运维工作转移给开发部门来控制整个部门的琐事占比。
对比思考:
“工作经常被打断,技术含量不高的问题太多,开发换了一轮又一轮、重复性问题回答了一遍又一遍…”等等,也是运维人员经常抱怨最大的问题。我们也老早安排了值班,但由于各个产品业务的独特性与复杂性,值班人员只能处理少部分日常工单,大部分的工单还是需要分配给非值班的人员,所以整体上每个人的日常琐事非常多,特别是咨询类工作,往往一个运维人员的 IM 对话飘窗达到 20 个以上。我们的应对之道:
- 小石头机器人能够回答常见 FAQ。文档和 FAQ,我们也有总结,让开发部门等能够学习,实践下来总体效果不理想。实时的交互式问答,问题更聚焦,对于用户来说是个更快更有效率的方式。为此,我们会尝试将 FAQ 做到智能客服机器人当中,在常用平台页面如夸父等接入小石头机器人,能够回答用户的常见问题。我们需要做的就是持续更新 FAQ,让智能机器人做到更精准匹配回答,并引导用户使用小石头。
- 值班能够处理更多工作,通过将日常工作规范化、平台化和 WEB 化,对值班人员屏蔽不同产品业务工作的独特性,依赖于我们各个平台自身的建设,后续将持续投入精力。
- 开放自助化,输出运维能力。通过流程控制、任务自动化处理和风险控制,利用夸父等平台让开发等部门能够自己处理日常需求,目前 NDP 发布平台、OWL 缓存管理等已有尝试,后续夸父新工单系统将会改造原有流程,在 Q3 开始实施工单自助化操作并持续开放更多类型工单的自助化。
4. 人才招聘与培养
谷歌 SRE 人才招聘,按照软件开发工程师一致的标准,并且 SRE 团队里也有各种行业背景的优秀人才,比如原先有负责美国国防部陆空运载设施的 GPS 与惯性制导系统的,原先是救生员的,原先设计军用飞机等地勤管理系统的,原先是合成砖石工厂的工程师的,原先是核潜艇工程师的等等,都是对安全性、稳定性、可靠性要求非常高的岗位。在培养方面建立体系化培训课程、学习事故经验总结、承担挑战性项目并尽早参与 on-call 见习工作。
对比思考:
我们做得还可以的:重视招聘,一直是我们部门的传统,做到各个招聘主管的招聘标准一致,除了考核专业能力之外对合作、执行等方面也确立了标准,另外专业能力上需要有工程化思想。以前有一个应聘者回答“为什么选择运维岗位”的时候,说道“自己不喜欢开发工作”,虽然各方面能力都不错我们还是没有选择她。
我们可以借鉴的地方:反向工程思维的培养,可以多做一些破坏性工作并修复的演练;多让新人承担一些有挑战性的项目。另外对于其他行业优秀的人才可以多加关注。
最后,开发与运维不是天然对立矛盾的,只是需要大家确立为产品发展的共同目标,在产品创新速度与稳定性之间寻求到平衡。我们在思考自身运维工作的时候,会始终坚持上面这个观点。以上是在看完谷歌 SRE 一书之后,我们结合自身工作做的一点点思考,以及后续我们工作改进的一些方向。